 |
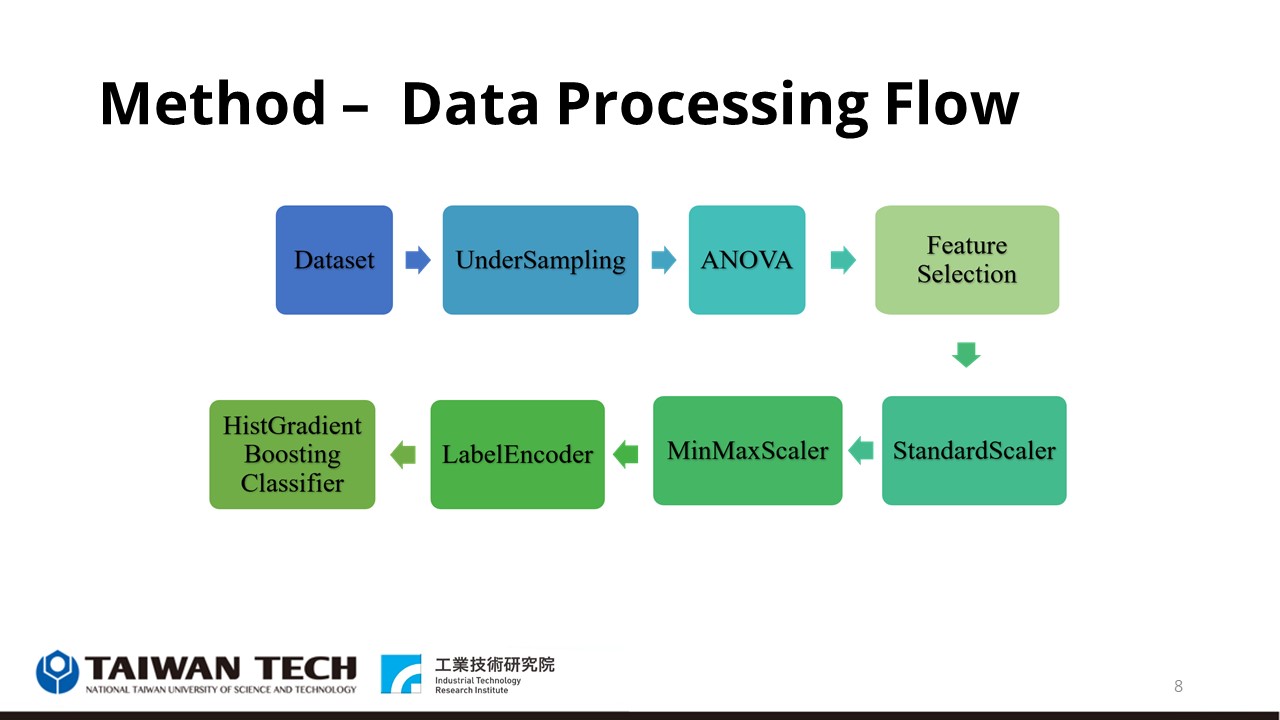
In the dataset processing, the three datasets were mixed and split into training and test sets with a ratio of 3:1. Then, the datasets were further analyzed for label uniformity and found to have unbalanced labels. In this study, we use the imblearn tool to perform data under-sampling to equalize the labeling ratio of the whole dataset. We then use the feature importance evaluation tool f_classif and the feature selection tool SelectKBest to perform feature filtering. First, the f_classif tool uses ANOVA (Analysis of Variance) statistics to assign P-values to each feature. Then the SelectKBest tool ranks the P-values of each feature and selects K features in the dataset for model training. Twenty features are finally selected for model training in this study.
After selecting the desired dataset features, data pre-processing is performed. The data pre-processing techniques use in this study are StandardScaler, MinMaxScaler, and LabelEncoder. First, StandardScaler is applied to each feature value to make the Gaussian distribution of each feature value so that the mean value of each group feature is zero and the standard deviation is one. Then MinMaxScaler is performed to reduce the range of each feature in the dataset from zero to one, and finally, the labeled data in the dataset is encoded by LabelEncoder.
|
 IEEE/ICACT20230167 Slide.08
[Big Slide]
IEEE/ICACT20230167 Slide.08
[Big Slide]