 |
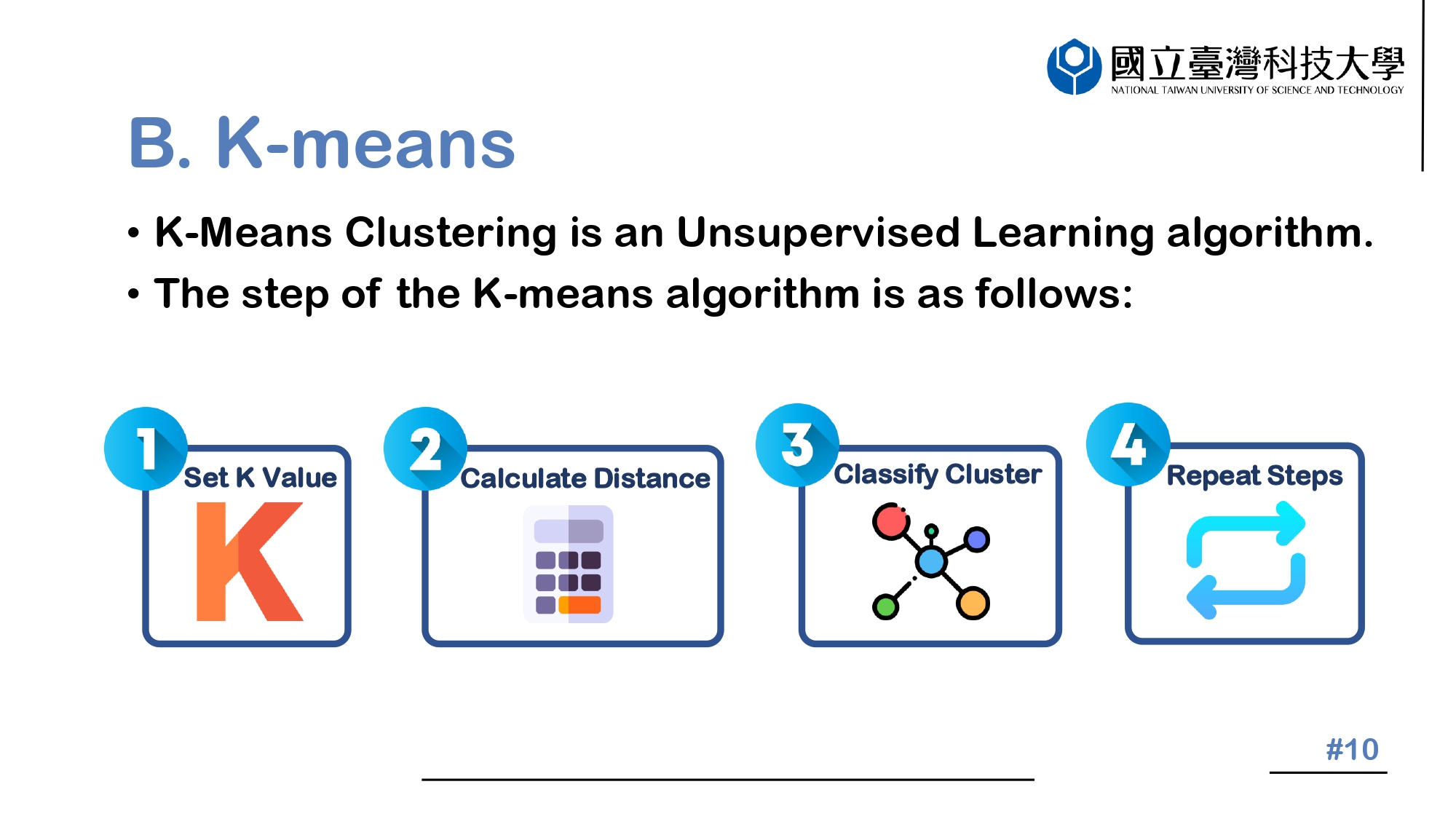
K-means algorithm is an unsupervised learning algorithm.
The processing flow includes the following: 1. The parameter K is first set, used as the number of cluster centers in the vector. 2. The cluster center is scattered in the vector space for each data. Calculate the shortest Euclidean distance between each data to all cluster centers. 3. Take the cluster with the shortest distance for each data and classify it as that. 4. Finally, repeat steps 2 and 3. Finish until all data points stay the same from the cluster center.
|
 IEEE/ICACT20230048 Slide.10
[Big Slide]
[YouTube]
IEEE/ICACT20230048 Slide.10
[Big Slide]
[YouTube]