Now 451 visitors
Today:158 Yesterday:931
Total: 2023
413S 88P 97R
2026-04-05, Week 15 |
| Member Login |
| Welcome Message |
| Statistics & History |
| Committee |
| TACT Journal Homepage |
| Call for Paper |
| Paper Submission |
| Find My Paper |
| Author Homepage |
| Paper Procedure |
| FAQ |
| Registration & Invoice |
| Paper Archives |
| Outstanding Papers |
| Author Homepage |
| - Paper Procedure |
| - Journal Procedure |
| - Presentation Tips |
|
| Program & Proceedings |
| Program with Papers |
| Plenary Session |
| Tutorial Session |
|
| Presentation Platform |
| Hotel & Travel Info |
| About Korea |
| Accommodation |
| Transportation |
| VISA |
| Other Infomation |
|
| Photo Gallery |
| Scheduler Login |
| Seminar |
| Archives Login |
|
| Sponsors |

|

|

|

|

|

|

|

|

|

|
|
|
|
|
main_email:isb6655@korea.ac.kr
| Save the slide and description |

|
*** You can edit any slide by selecting the Slide number below***
|
 ICACT20220171 Slide.15
[Big slide for presentation]
[YouTube]
ICACT20220171 Slide.15
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! Click!! |
 |
Thank you for listening!
|
|
ICACT20220171 Slide.14
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
We consider the system model[7] to find the optimal offloading policy and partitioning in MEC. Detailed formulas for obtaining cost and system parameters can be found in [7].
|
|
ICACT20220171 Slide.13
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
This paper proposed a deep learning-based partial offloading method in MEC systems for various scenarios. Two DNNs were employed for the selections of the partitioning of a single task and their offloading policy to solve the multiclass classification problems, respectively. For partitioning selection, the ratio of task size instead of the actual task size was considered as label data. The performance of the proposed method was evaluated in various scenarios. The simulation results showed that the proposed method has more than 77% and 89% classification performances for partitioning and offloading selection, respectively, in various scenarios. Applying appropriate weights depending on the application-specific requirements will reduce latency and energy. Our future work is to find a way to further increase accuracy by using a local search algorithm for the partitioning classification selection.
|
|
ICACT20220171 Slide.12
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
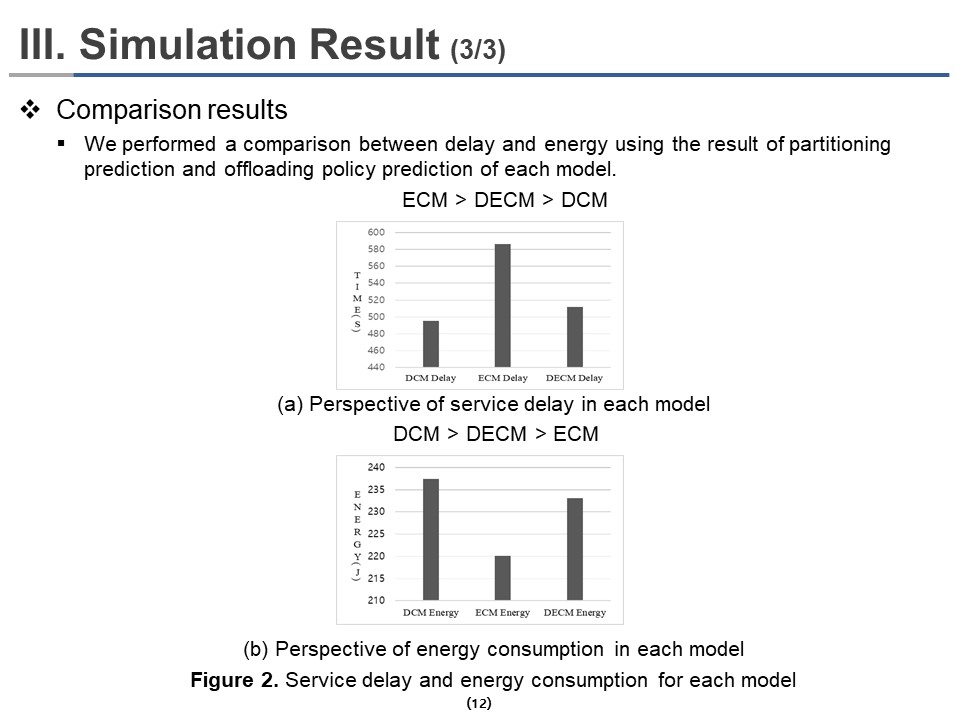 |
Figure 2 shows the results of the effect of delay and energy weighting on actual delay and energy by DCM model, ECM model, and DECM model, respectively. We performed a comparison between delay and energy using the result of partitioning prediction and offloading policy prediction of each model.
Figure 2(a) shows the comparison results from the perspective of delays in each model. As we adjusted the weight coefficient, the DCM model had the shortest delay, and the DECM model had the second short delay. The ECM model showed the most prolonged delay because the delay does not matter in the ECM model. Figure 2(b) shows the comparison results from the perspective of energies in each model. Similarly, the ECM model had the lowest energy consumption, followed by the DECM model with the second-lowest energy consumption, and the DCM model showed the highest energy consumption.
|
|
ICACT20220171 Slide.11
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
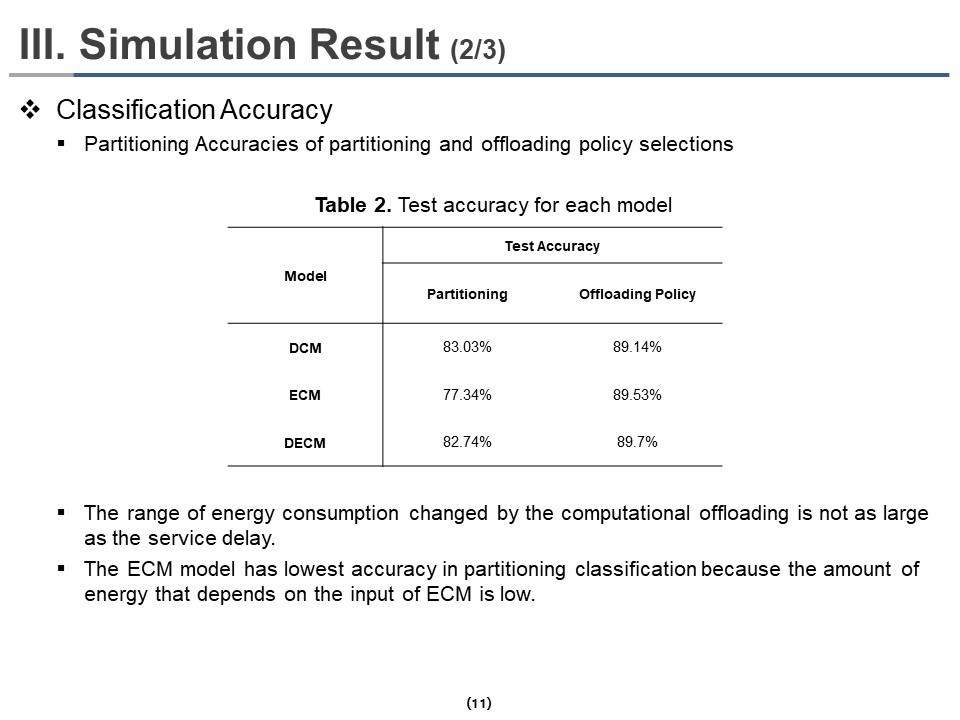 |
Table 2 shows the classification accuracies of partitioning and offloading policy selections. The classification performances of partitioning are 77% to 83%, and the classification performances of offloading policy are 89% for all models. The ECM has the lowest accuracy in partitioning classification because the amount of energy that depends on the input of ECM is low
|
|
ICACT20220171 Slide.10
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
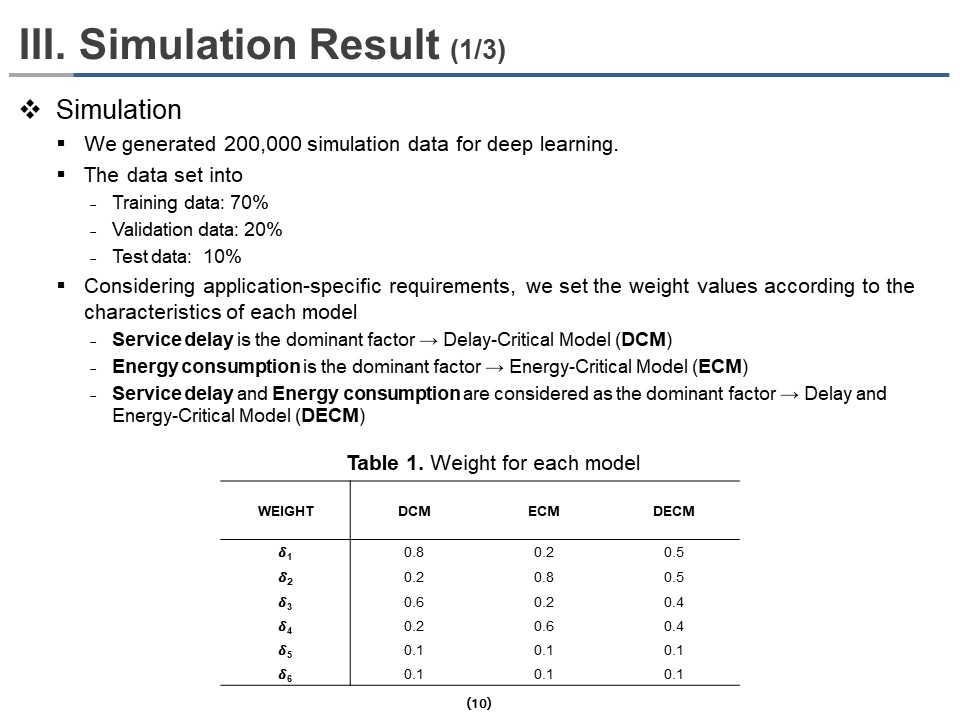 |
We generated 200,000 simulation data for deep learning. The data is randomly divided into training, validation, and test data by 70%, 20%, and 10%, respectively.
(system model part) We identify and analyze how changing the weight factors that determine delay and energy prioritization affect delay and energy changes when performing offloading. To consider various delays and energy priorities, we evaluate the energy consumption and service delay of partial offloading by setting weighting coefficients according to three scenarios.
Table 1 shows the weight coefficient of the three models. Considering application-specific requirements, we set the weight values according to the characteristics of each model. We considered three different models, which are the delay-critical model (DCM), energy-critical model (ECM), and delay and energy-critical model (DECM).
|
|
ICACT20220171 Slide.09
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
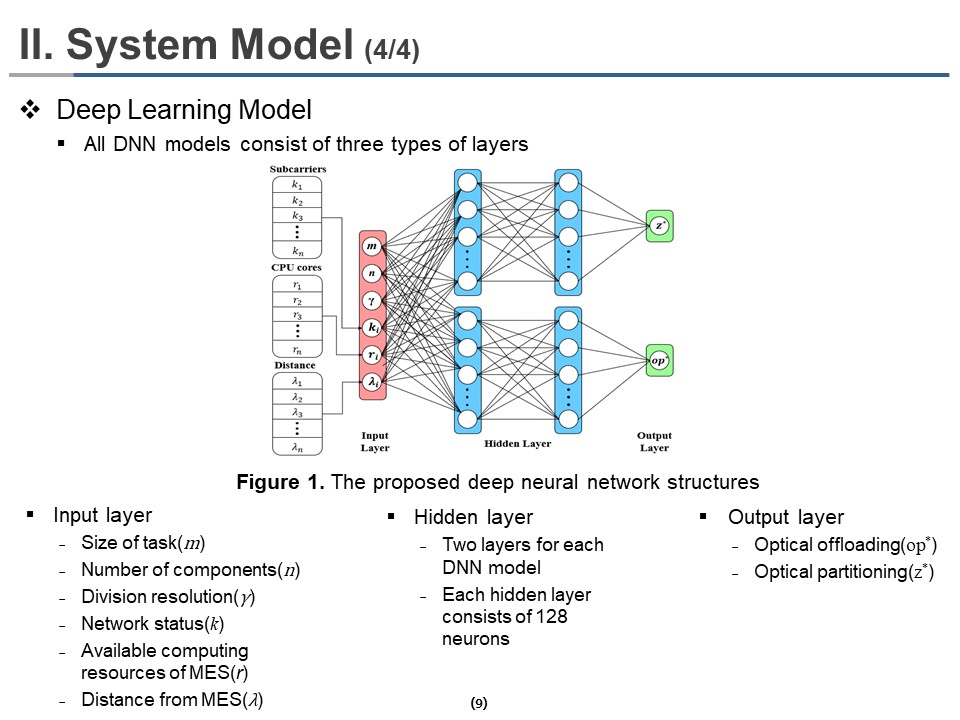 |
All DNN models consist of three types of layers. It consists of an input layer, a hidden layer, and an output layer. The input layer consists of the information about the size of the task (m), the number of components (n), division resolution (γ), network status (k), available computing resources of MES (r), distance from MES (λ). The hidden layer consists of two layers for each deep neural network model. Each hidden layer consists of 128 neurons. Each of the two output Layers provides different information, one output layer for optical offloading policy(op*) and another for optimal partitioning(z*). Overall DNN structures are shown in Figure 1.
Therefore, 21 neurons in the input layer; a neuron for task size, a neuron for the number of components per task, a neuron for division resolution, six neurons for random distances during mobility of UEs in the execution of each component, six neurons for subcarriers during the execution of each component, and six neurons for CPU cores assigned to each component. Similarly, six neurons for offloading policy and six neurons for partitioning are reserved in each output layer. The ReLU and Softmax activation functions are used for the hidden and the output layers, respectively.
|
|
ICACT20220171 Slide.08
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
To reduce very large computational complexity, we use a supervised learning approach. The DNN performs offloading and partitioning selections based on the given input values. The conventional DNN structure could exponentially increase the combination of classes between partitioning and offloading policy. To solve this problem, we divided a single DNN into two DNNs; One DNN for optimal work partitioning and the other for determining the offloading method for each component.
We selected and saved the option and input data with minimum cost to generate a dataset for training deep neural network models. We randomly generated task size, number of components, division resolution, number of subcarriers, available computing resources of MES, the distance between UE and MES, frequency of UE, transmitting power of UE to consider simulations in various situations.
|
|
ICACT20220171 Slide.07
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
fco(ci) indicates the remote cost when ci executes remotely on MES, where ci is the ith components of a single task. The cost function for remote execution fco(ci) can be described as follow.
Where δ3, δ4, δ5 and δ6 are the weighting coefficient by which we can change the contribution and priority of time delay, energy consumption, radio resources, and computational resources in the cost function. We set the sum of all coefficients to be 1. In the delay parameters, dti, dei, dri, and dpi are delays due to transmission, execution, reception, propagation for remote execution of ci, respectively. Eti and Eri are the energy consumption in the energy parameters due to transmission and reception for remote execution of ci, respectively. We multiply (1 – ei-1) with dti and Eti if the previous component ci-1 was executed at MES, where ei is an indicator that means 0 when ci executes locally and 1 when ci executes remotely at MES. It means the next component ci is available at MES and does not need to be retransmitted. Similarly, dpi (2 – ei-1) gives propagation delay only for reception. f2(ri) and f3(ki) give the cost due to used CPU cores and subcarriers, respectively, where ri represents the number of CPU cores used to process ci and ki represents the available subcarriers of ci.
|
|
ICACT20220171 Slide.06
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
In the system model section, we present a method of calculating the cost function for partial offloading and deep learning model structure. fcl(ci) indicates the local cost when ci executes locally in the UE where ci is the ith components of a single task. The cost function for local execution fcl(ci) can be calculated as follow.
where δ1 and δ2 are the weighting coefficient by which we can change the contribution and priority of delay and energy consumption in the local cost function, respectively. In the delay parameters, dli is a total delay for local execution of ci, ddi is a time delay for task-division per component, and dmax is the deadline time for whole task execution. In the energy parameters, Eli is total energy consumption for local execution of ci, Edi is energy consumption for partitioning the task, and Emax is the maximum energy of UE's battery.
|
|
ICACT20220171 Slide.05
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
To reduce the number of classes for partitioning and offloading policy selections, we first used two DNNs for partitioning and offloading policy selections, respectively. It could significantly reduce the combination of classes between partitioning and offloading policy. Second, the class for partitioning selection is generated through a ratio of size rather than actual size. It mitigates the rapid increase in the number of classes as data size increases. The proposed method uses two techniques to perform classification tasks through significantly reduced classes, enabling low complexity and reliable selections for partitioning and offloading policy.
As I mentioned earlier, Performance comparison and analysis are performed through various models in environments where service delay is the dominant factor, energy consumption is the dominant factor, and service delay and energy consumption are considered the dominant factor.
|
|
ICACT20220171 Slide.04
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Several computational offloading methods have been introduced to minimize UE service delay and energy consumption in MEC systems. These methods are compared and analyzed from the perspective of a service delay, energy consumption, task partitioning, and deep learning.
The deep learning-based partial offloading method consumes less energy with faster execution in MEC networks than the conventional methods. However, this method performs multiclass classification with numerous classes by combining partitioning and offloading policies. So, the number of class partitioning and offloading policies increases exponentially as the data size of a single task and the number of components per task increases.
|
|
ICACT20220171 Slide.03
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
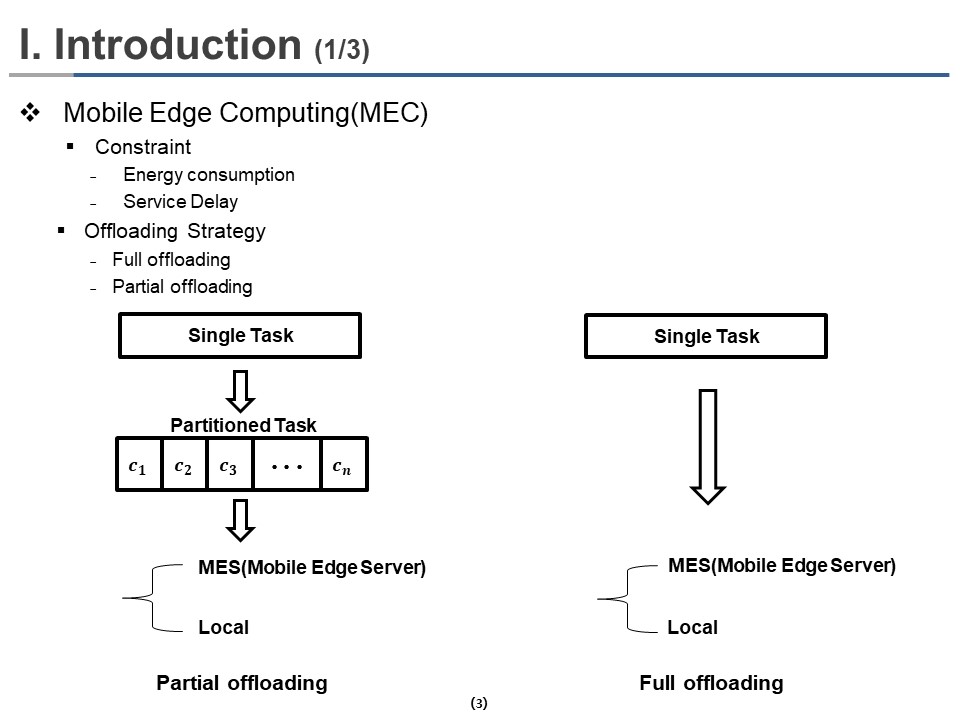 |
Mobile Edge Computing (MEC) technology has emerged to reduce the Energy Consumption and Service Delay of User Equipment (UE) by deploying powerful computing and storage capacity when the computing tasks are offloaded to Mobile Edge Server (MES).
The offloading strategy can be categorized into Full offloading and Partial offloading. In Partial Offloading, the single task is divided into several components. Then some of the components are offloaded to MES for execution, while the whole task is offloaded to MES for execution in full offloading.
Finding an optimal partial offloading policy is complicated because the number of possible ways of Task partitioning increases exponentially with the task size.
|
|
ICACT20220171 Slide.02
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
The problem of offloading policy is addressed for mobile edge computing (MEC) in this paper.
The proposal is a deep learning-based partial offloading technique to reduce user equipment's energy consumption and service delay. The proposed method consists of two deep neural networks (DNNs) to find the best partitioning of a single task and their offloading policy, respectively.
The DNN learned from the ratio of task size, not the actual task size, to improve the classification accuracy.
The performance of the proposed method was evaluated in three scenarios which are delay-critical model (DCM), energy-critical model (ECM), and delay and energy-critical model (DECM).
The simulation results show that the proposed method has more than 77% and 89% classification performances for partitioning and offloading in various scenarios.
|
|
ICACT20220171 Slide.01
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
.jpg) |
Hi everybody, my name is Seokbeom Oh. For ICACT 2022, I and Professor Hyun-kook Kahng have cooperated with two professors. Professor Yong-Geun Hong from Daejeon University, and Professor Gyuyeol KONG from ChoungShin University. Today, our presentation is about the computational offloading method called Performance Evaluation of Three Partial Offloading under Various Scenarios in Mobile Edge Computing.
|
| |





