 ICACT20230209 Slide.15
[Big slide for presentation]
ICACT20230209 Slide.15
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! Click!! |
 |
Thanks
|
|
ICACT20230209 Slide.14
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
References
|
|
ICACT20230209 Slide.13
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
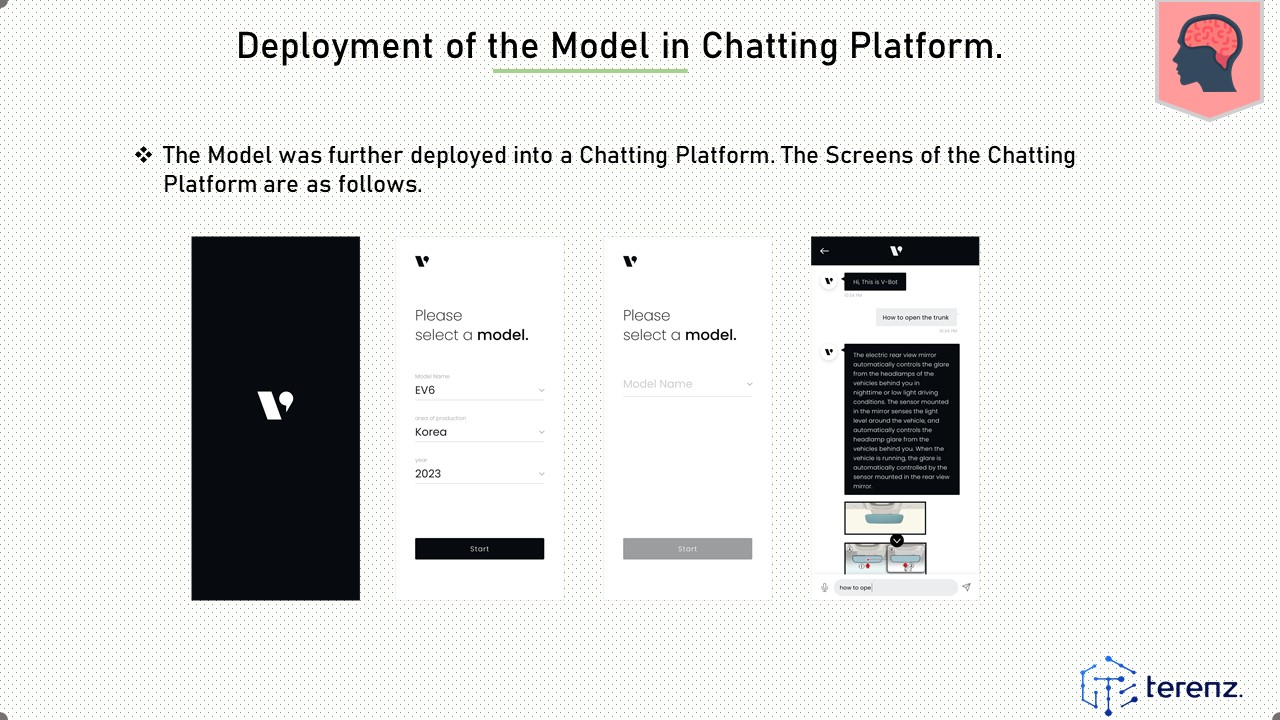 |
The Model was further deployed into a Chatting Platform. The Screens of the Chatting Platform are as follows.
|
|
ICACT20230209 Slide.12
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The Adam (Adaptive Moment Estimation) [8] optimizer was used by the Intent Classification Model established in this work to optimize the cost function, which is the categorical cross-entropy.
The optimizer algorithm Adam's hyperparameters were tuned using Bayesian Sequential Model Optimization. Bayesian SMBO is a hyperparameter optimization that reduces a specific objective function by building a surrogate model from the objective function's prior evaluation results
The set of hyperparameters that were chosen for the optimizer function were as follows, learning rate: 0.0001, beta-1: 0.93241, and decay: 0.0000024.
|
|
ICACT20230209 Slide.11
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
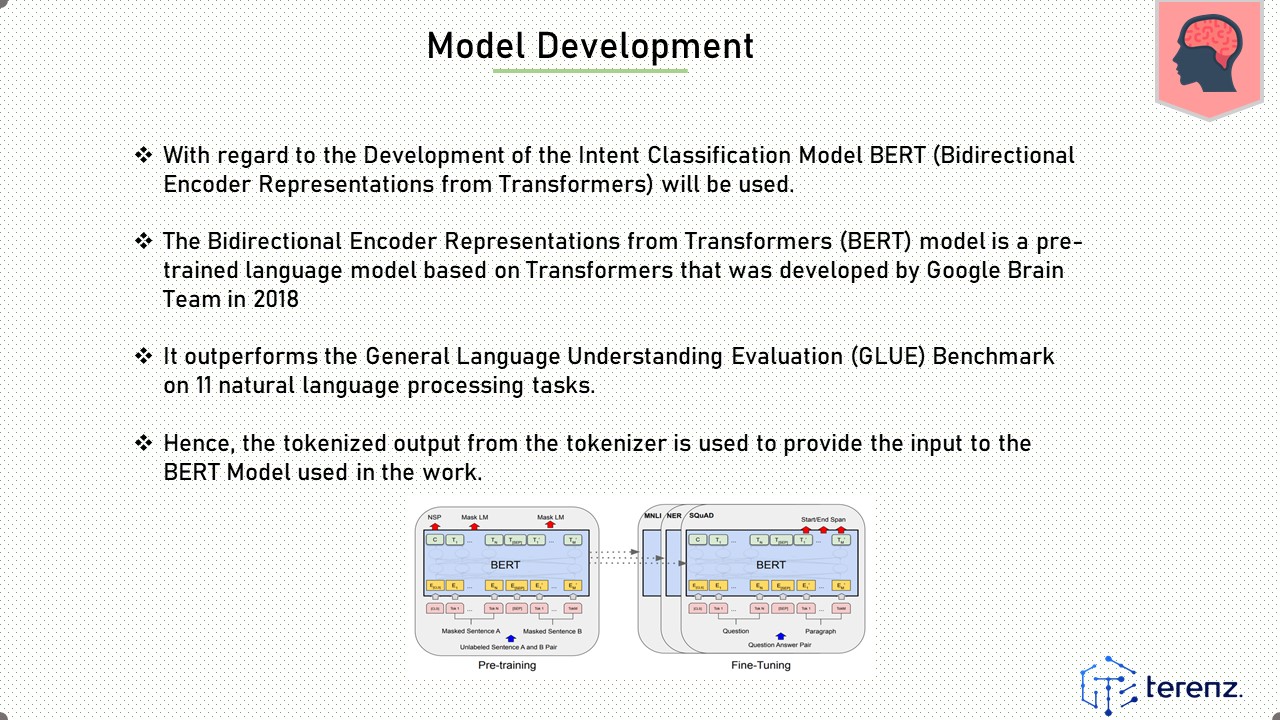 |
With regard to the Development of the Intent Classification Model BERT (Bidirectional Encoder Representations from Transformers) will be used.
The Bidirectional Encoder Representations from Transformers (BERT) model is a pre-trained language model based on Transformers that was developed by Google Brain Team in 2018
It outperforms the General Language Understanding Evaluation (GLUE) Benchmark on 11 natural language processing tasks.
Hence, the tokenized output from the tokenizer is used to provide the input to the BERT Model used in the work.
|
|
ICACT20230209 Slide.10
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
For feeding the Training Data to the Intent Classification Model, the data needs to be converted into a sequence of tokens which will be further substituted as an integer.
Therefore, for creating Tokens the Text will be Tokenized and will be converted to the tokens using the developed Named Entity Recognition Model.
|
|
ICACT20230209 Slide.09
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The Tokenization and Named Entity recognition of the Text is of primary importance to feeding the data to the BERT Input layer of the Model.
Moreover, the conversion of the text to numbers must be done in a way where the tokenization of a specific named entity in the text should be established with a specific id.
For the Named Entity Recognition, the test sequences were tokenized and each token was labelled with Five (5) types of classes (O, B-Comp, I-Comp, B-Task, I-Task).
Table below shows the distribution of each class and also the definition of each class to which a specific token is mapped.
|
|
ICACT20230209 Slide.08
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Special Characters and Stop Words must be removed for proper model training.
As the Intent Classification is specifically for the owner’s manual of the car, therefore, the questions are accepted to be somewhat technical hence the flow of the questions is less important than the objects in the questions.
Special characters such as (Question Marks (?), Commas (,), Exclamation Mark (!), Colon (:) were completely removed from all the text.
|
|
ICACT20230209 Slide.07
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The dataset for the Training of the Intent Classification model for the Natural Language Understanding System of the Owner’s Manual Chatbot was created and curated by TLA Solution Co., Ltd.
The classes or the labels of the dataset were the intents that can be the destination of a user’s question at a given instance.
The features on the other side were the questions that can be asked by any user concerning a particular intent.
|
|
ICACT20230209 Slide.06
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Flow of the Process
Data Acquisition and Processing
Data Preprocessing
Model Development
Performance Evaluation
Deployment of the Model in Chatting Platform.
|
|
ICACT20230209 Slide.05
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
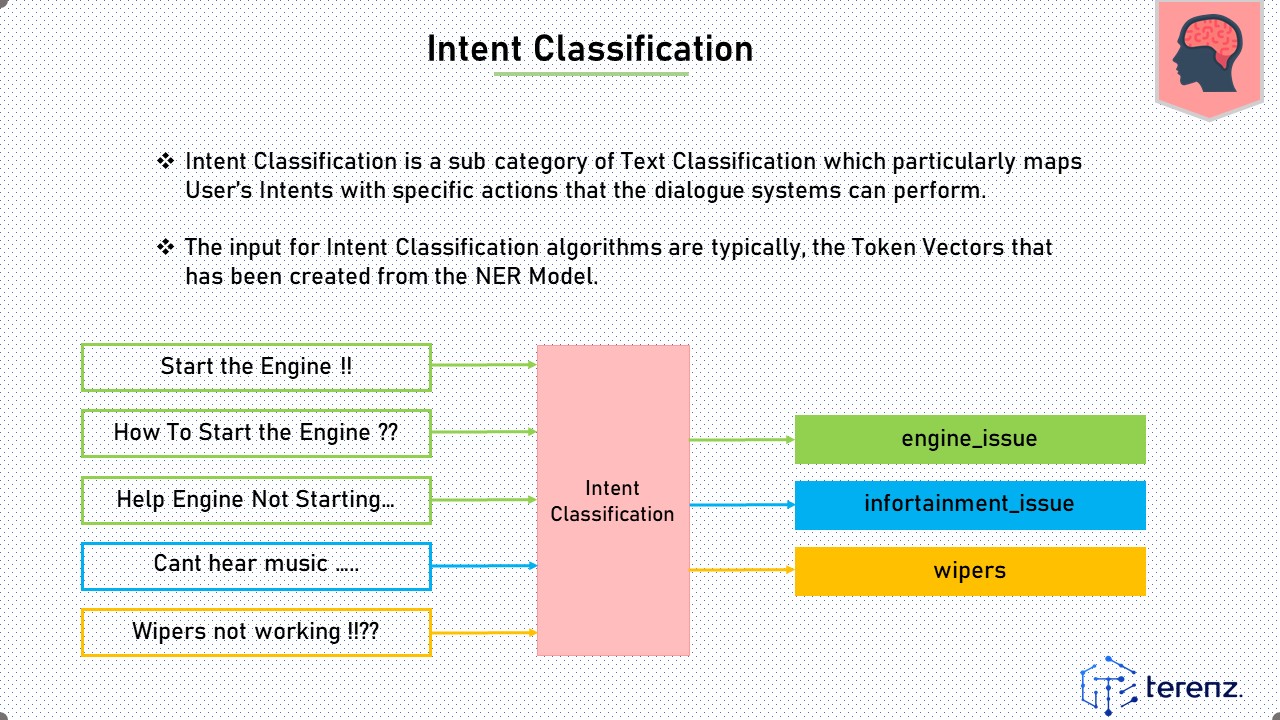 |
Intent Classification is a sub category of Text Classification which particularly maps User’s Intents with specific actions that the dialogue systems can perform.
The input for Intent Classification algorithms are typically, the Token Vectors that has been created from the NER Model.
|
|
ICACT20230209 Slide.04
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Named Entity Recognition Models are used to understand what are the entities that are present in the input text of the user.
The Entities are specifically, words that represent specific attributes in a User Query or User Input.
Moreover, conversion of the text to numbers must be done in a way where the tokenization of a specific named entity in the text should be established with a specific id.
|
|
ICACT20230209 Slide.03
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Natural Language Understanding is a method that primarily uses its ability to understand the queries or questions or inputs of the user.
The Natural Language Understanding pipeline helps the complete system to decide the actions or output that the Dialogue System needs to take with respect to a particular query of the user.
The Natural Language Understanding Pipeline is primarily powered by Named Entity Recognition Model and Intent Classification Model for understanding the input of the user or the Human Agent.
|
|
ICACT20230209 Slide.02
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Conversational Dialogue Systems is a software application used to conduct an online chat conversation via text or text-to-speech, in lieu of providing direct contact with a live human agent.
Conversational Dialogue Systems are predominantly used in all kinds of industries to increase the efficiency and seamlessness of Human-Agent to Business Interaction.
A Conversational Dialogue System comprises of multiple systems such as NLU(Natural Language Understanding) Pipeline, Response Server and Dialogue Management Core for the quick and accurate flow of conversations.
The usage of Conversational Dialogue Systems in customer faceted business have shown huge benefits.
|
|
ICACT20230209 Slide.01
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Hello, This is Sabyasachi from Terenz Co., Ltd, Busan, South Korea.
Today I am going to present my paper on Intent Classification of Users Conversation using BERT for Conversational Dialogue System.
|
|
ICACT20230209 Slide.00
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Youtube
|









