 ICACT20240417 Slide.29
[Big slide for presentation]
ICACT20240417 Slide.29
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! Click!! |
 |
Thank you for listening
|
|
ICACT20240417 Slide.28
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Finally, we acknowledge related work that we reference in this research
|
|
ICACT20240417 Slide.27
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Finally, we acknowledge related work that we reference in this research
|
|
ICACT20240417 Slide.26
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
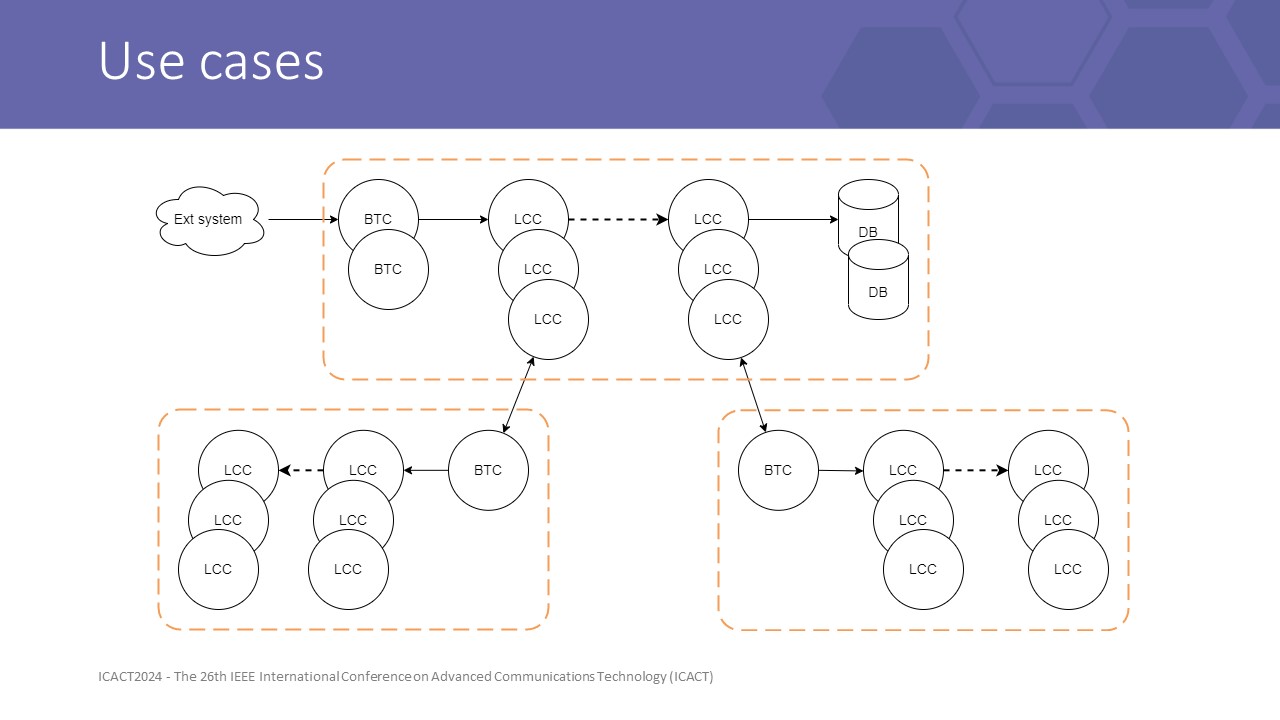 |
secondly, LCC delivers high performance if system capacity is well managed, so the LCC strategy is the most suitable for internal routing with higher resource efficiency, while BTC should be used for border gateways to maintain overall QoS.
|
|
ICACT20240417 Slide.25
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
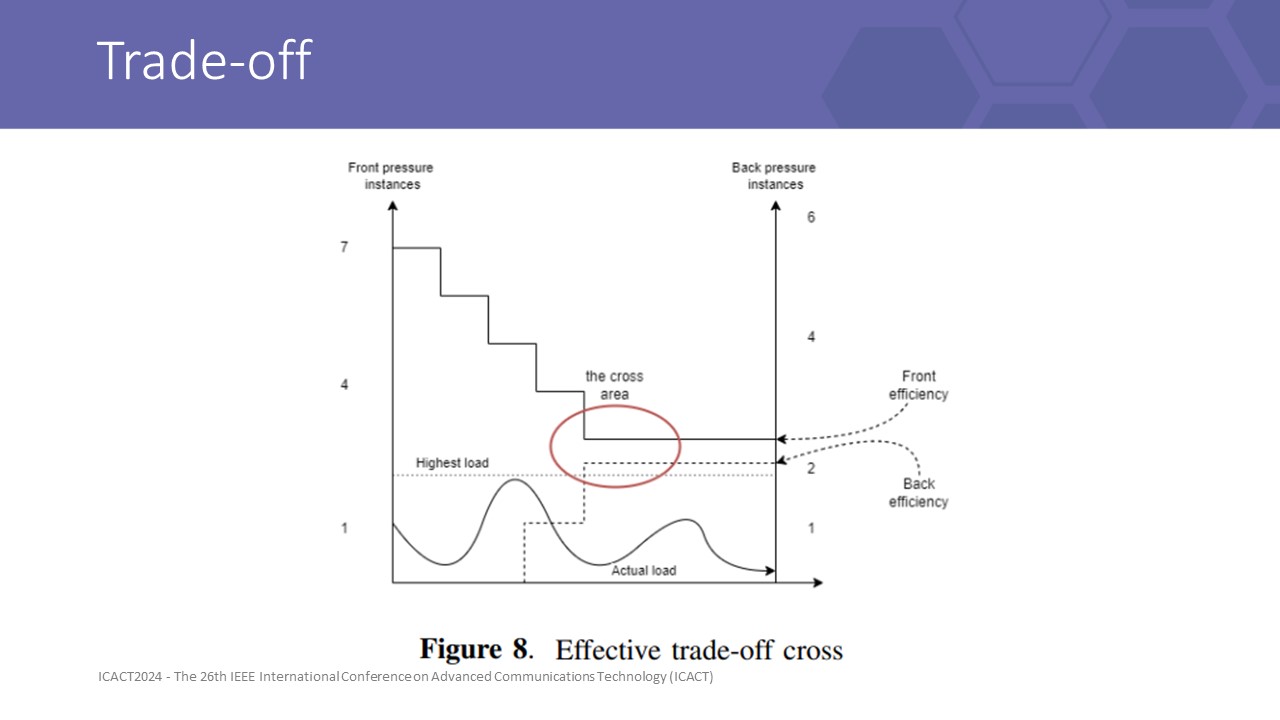 |
As shown in Figure 8, there was a cross between increasing performance efficiency due to more flow control policy, and decreasing resource usage pre-sized by the frontpressure layers. Front-pressure layers rely on pre-allocating and auto-scaling instances to prevent incidents caused by any throughput changes. Besides, back-pressure can maintain the throughput near the instance’s maximum capacity and guarantee QoS during scaling events, by mitigating message overflow into a manageable early drop reply stream, until more capacity is provisioned.
this trade between the overhead of backpressure with the redundant gap for front pressure to obtain the finest output KPI.
Therefore in an unstable mesh, we advise each service layer should enable a backpressure strategy. This is a fair trade of performance for instance safety
|
|
ICACT20240417 Slide.24
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Based on the result we obtained, we will give some advice for the lib connection approach strategies
|
|
ICACT20240417 Slide.23
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
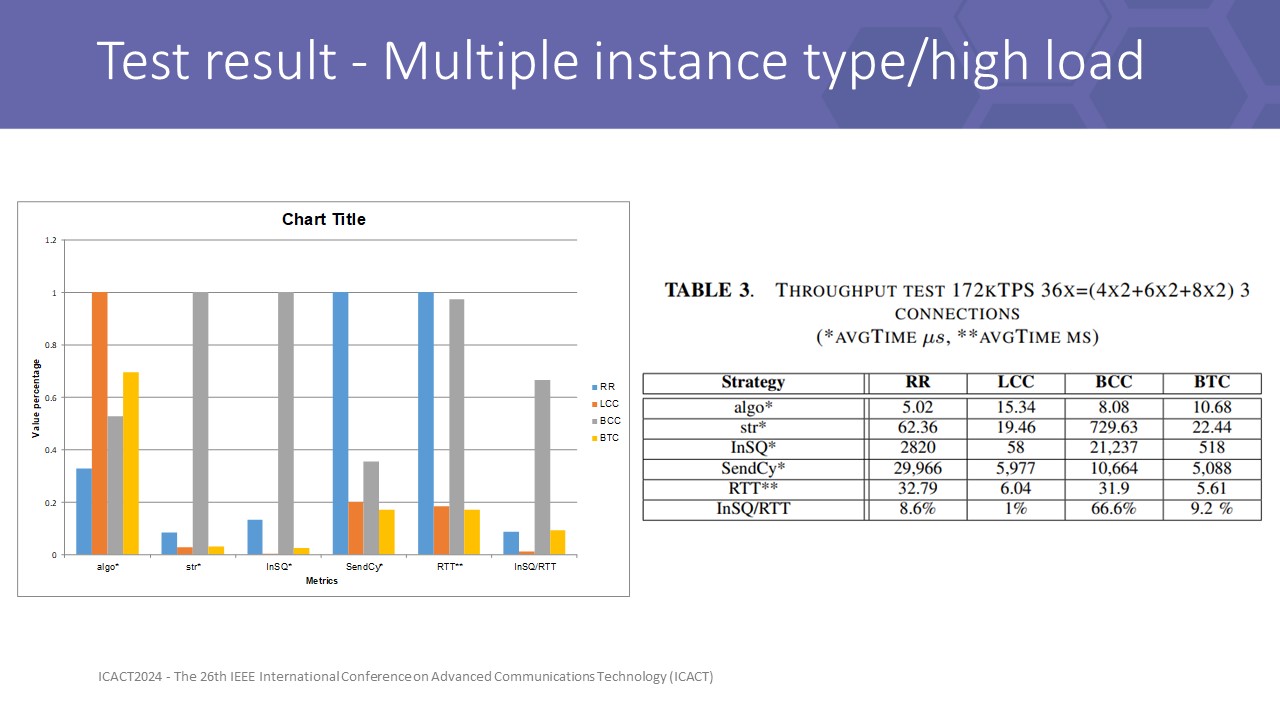 |
Increasing the instance size to 4 cores on 36x total size for 6 instances, and full load test with 172kTPS, the result here shows a different story. All strategies responded with 172kTPS throughput but LCC and BTC control the RTT time better and satisfy URLLC requirement.
Latency in the RR setups absorbed incoming pressure, which was reflected in the unacceptable RTT, avgTime:SendCy, and avgTime:InSQ to tens of milliseconds.
BCC struggles with small streams when the minimum CC is 2. With 6 instances open 3 connections per dest, each flow only transmits average throughput of about 9600TPS, this is under the threshold of a single CC connection, about 11kTPS, therefore BCC cannot control some slow flows, then the average result of BCC is extremely bad
Among front-pressure results, LCC proved itself to be a great competitor to RR. If the load is mostly lower than the capacity, utilizing back-pressure anywhere in the mesh leads to resources wasted. Front-pressure strategies are thus the most effective.
|
|
ICACT20240417 Slide.22
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
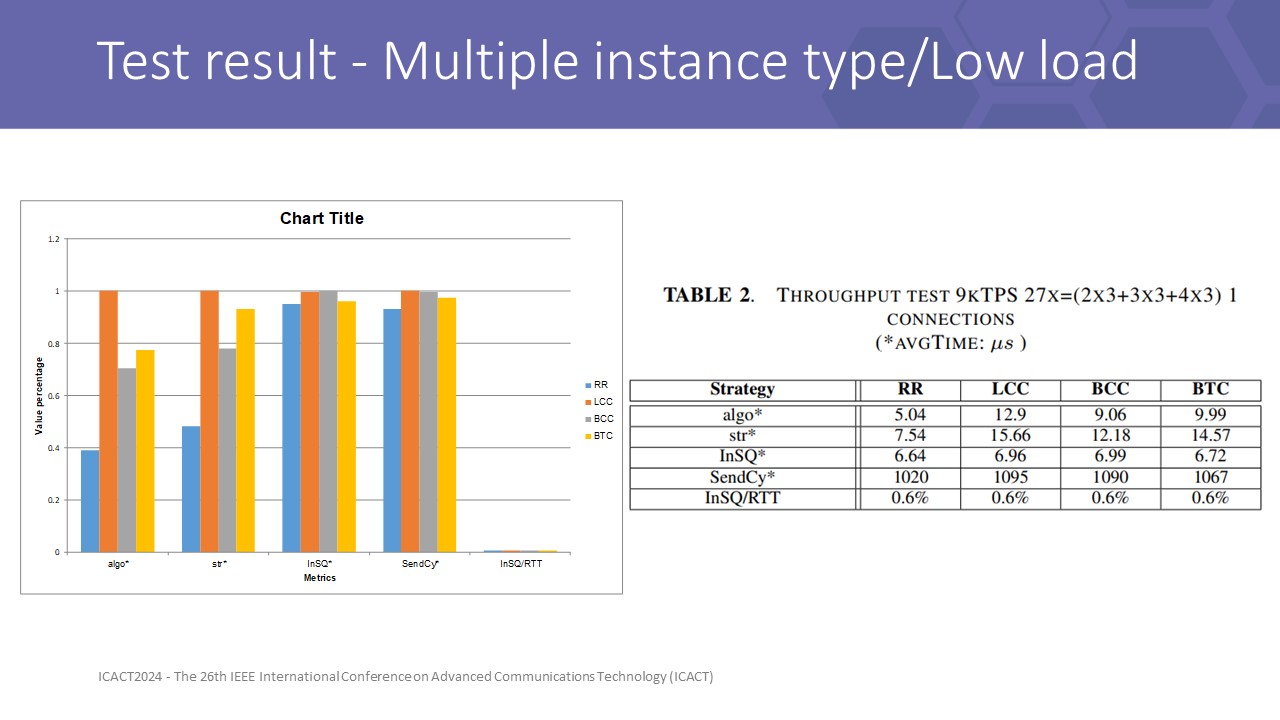 |
Underload at 9kTPS in total 27x of 9 instances with each type spawn 3 pods. The result in Table 2 shows that all methods are qualified with minor differences in the underload test.
the result showed only differences in algo and strategy time. The algo is the time for routing decision, and str time is the total time for decision and waiting until messages can be flush.BTC gain str time most around 4.5microsecond for CC lock, more than RR at 2.5microsec based. Moreover, the time to account algo of O(n) strategies nearly double as RR at O(1)
RTT time of 4 methods is approximate, so we can see backpressure under load work as effective as front pressure in this implementation
|
|
ICACT20240417 Slide.21
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
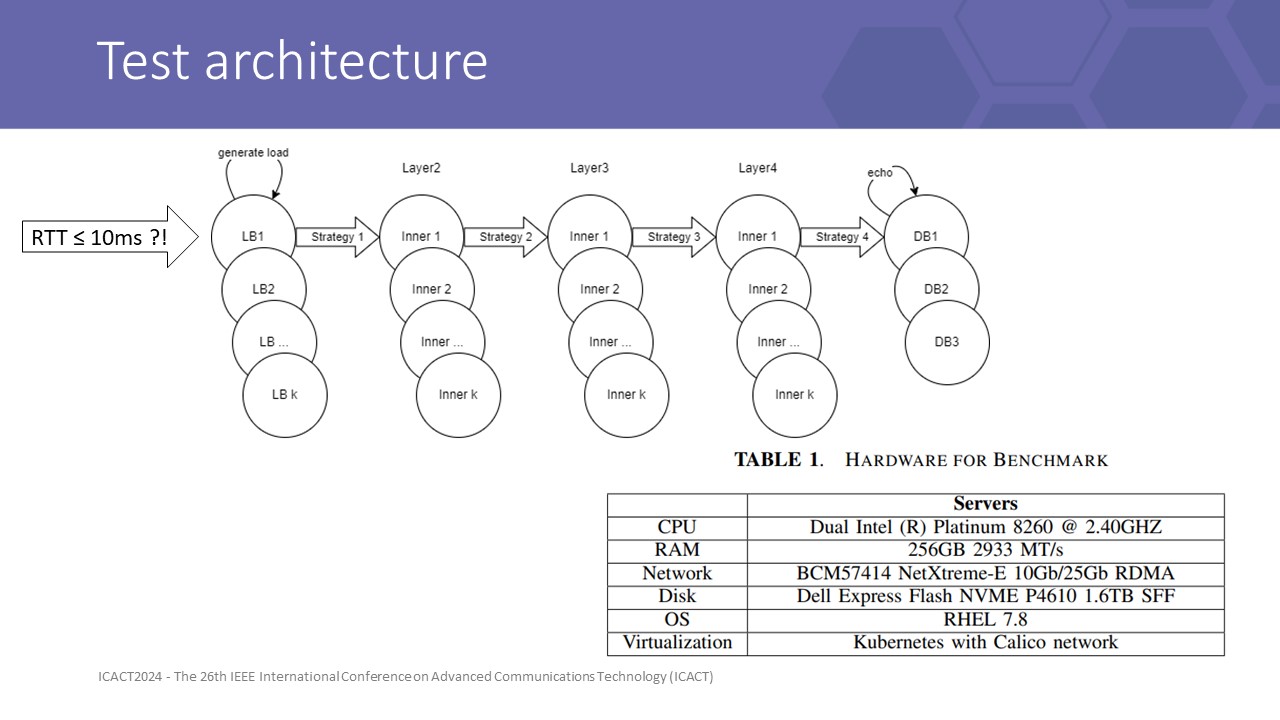 |
Our testbed is designed as shown on the screen.
the database is simulated by an echo server.
Each inner application is a homogeneous single-flow instance layer. API gateway (LB) is a modified application that has generator threads, that generate random fields 4KB messages in ByteBuf format into LB incoming queue.
Each service layer is deployed into 1 specific non-overlapping physical node to force all requests must travel over the physical network rather than some travel internal by localhost. URLLC defines 1-way latency for data planes less than 1 ms. Within 5 layers, we have 4 inner connected layers, with 2-way connections to an external (source) system. Therefore, 10ms is the upper bound of the transmit latency.
We record log at multiple layers and conclude by results at LB to give us a view of front-line queue status and send cycle time statistics (over client component of LB) as the latency a physical LB must wait: RTT = InSQ:avgTime + SendCy:avgTime.
We divided our scenarios into 2 dimensions:
• Sizing dimention: 2x 3x 4x 6x 8x with 1x = 1 vCore CPU + 1.5GB physical memory. With each scale, application configures like handleThread, Xmx, CPU factor, ... scaled proportionally.
• Load dimension: underload/highload.
To archive 99% of the confidence level at a 5% margin error of unlimited population, we collect 666 data samples with 1s windows since the first 100 skipped, matched timestamps from data points spanned among layers instances.
Log4j logging is enabled for statistics and errors. Statistics is accounting per interval (1s) by Windows.
|
|
ICACT20240417 Slide.20
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
To simulate the effectiveness of algorithms and our formula, we benched performance among four methods: RR, LCC, BCC, and BTC.
RR and LCC are the most popular methods in the group of front pressure methods, with RR being the naive, simplest, and most effective option for low-load systems.
LCC is a method of grouping ”least-X” over a metric X.
BCC is the most basic form of back pressure over a single metric method and to prove control only on dimension concurrency can throttle throughput.
In contrast, BTC is a testing method that combines backpressure over multiple metrics and can be the base for tuning and learning flow control algorithms.
|
|
ICACT20240417 Slide.19
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
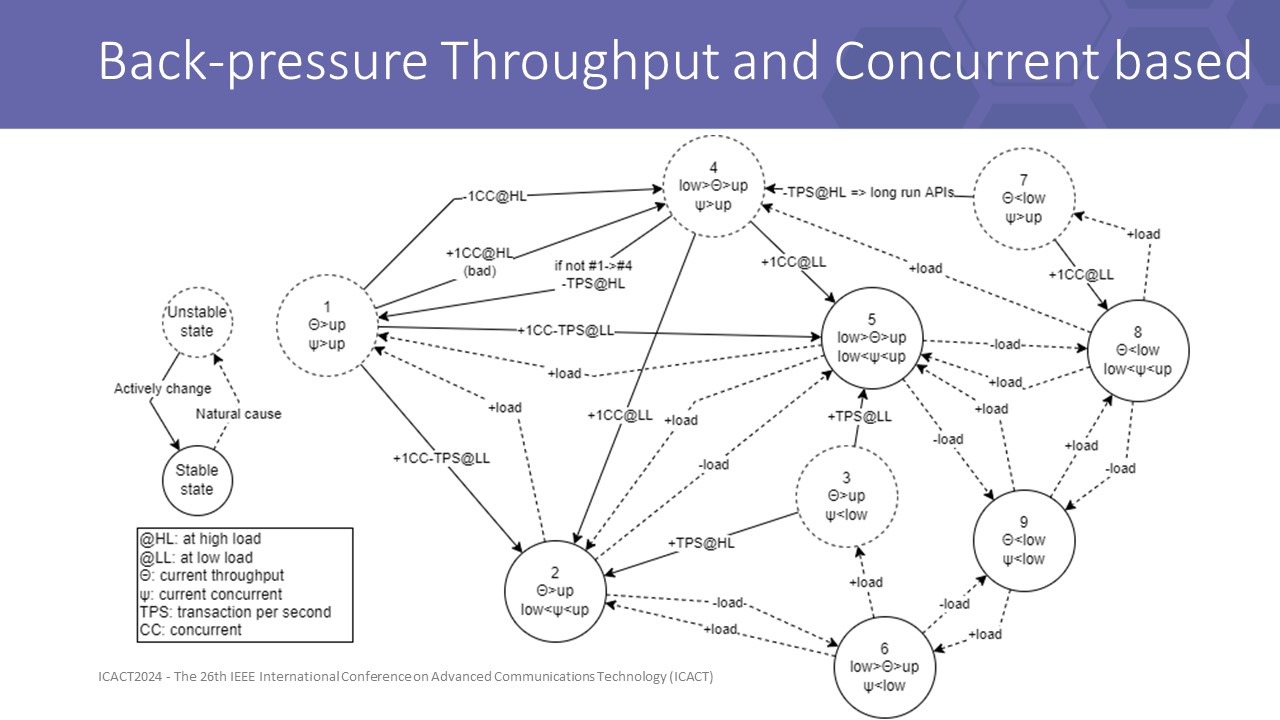 |
similarly, BTC leverage 2 dimensions of the flow and then create 9 segments by meshing 3 segments of throughput config and 3 segments of concurrent config to determine more detailed situations
different from BCC, BTC directly controls the throughput of the flow, giving LB a more robust method as shown in the following results
In this graph, we can see unstable states are danger states, including cases that concurrent state in high value, throughput state in high value, or both.
Transitioning like from state 5 to 1 has 2 actions apply to both dimention, and look at transition from 1 to 4 we can easily notice a loop.
The implementation is tunned to break this loop to converge to stable states
|
|
ICACT20240417 Slide.18
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
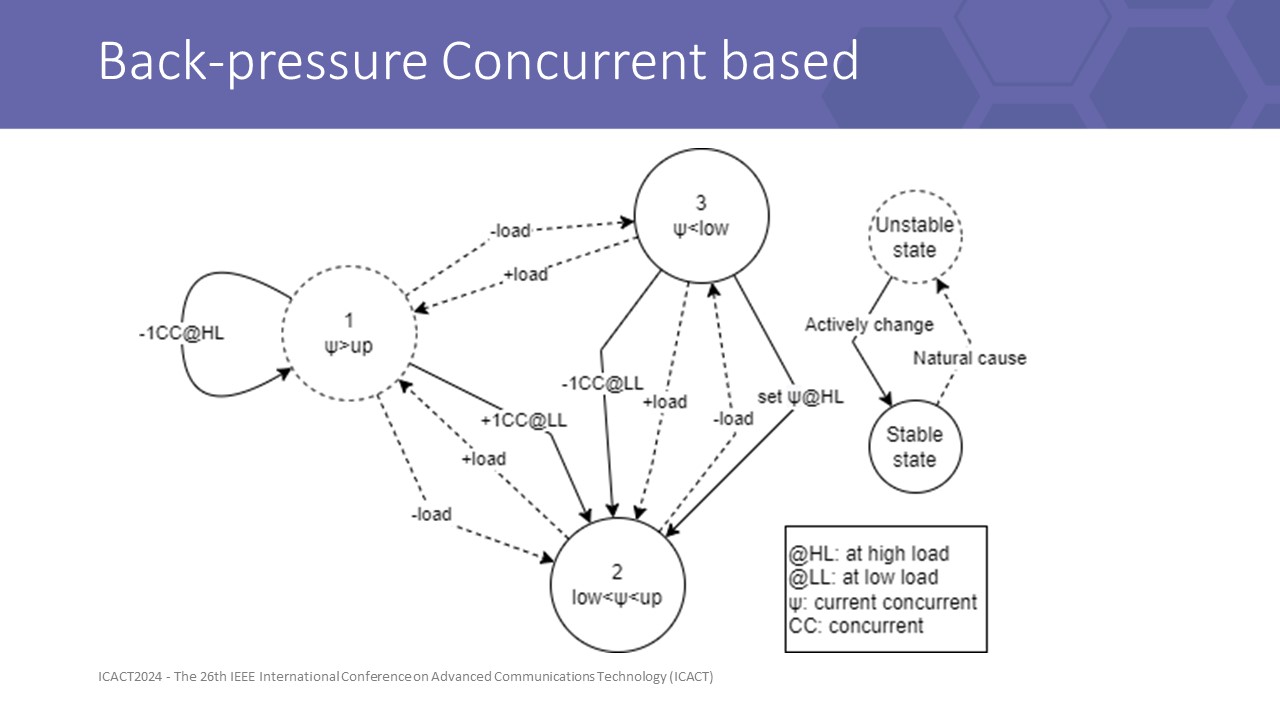 |
to test our formulas, we design 2 new back-pressure strategiesthe first is BCC, with it FSM is shown here
we divided configured concurrent value as 3 segments by 2 thresholds, upper and lower, in order are high usage, normal usage, and low usage
those segments combine with the load information of the peer, then auto-tune for the configuration up or down to maintain a suitable config for each connection
the dashed line show transitions of natural causes and the continuous line is the function action against an unstable state to
|
|
ICACT20240417 Slide.17
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
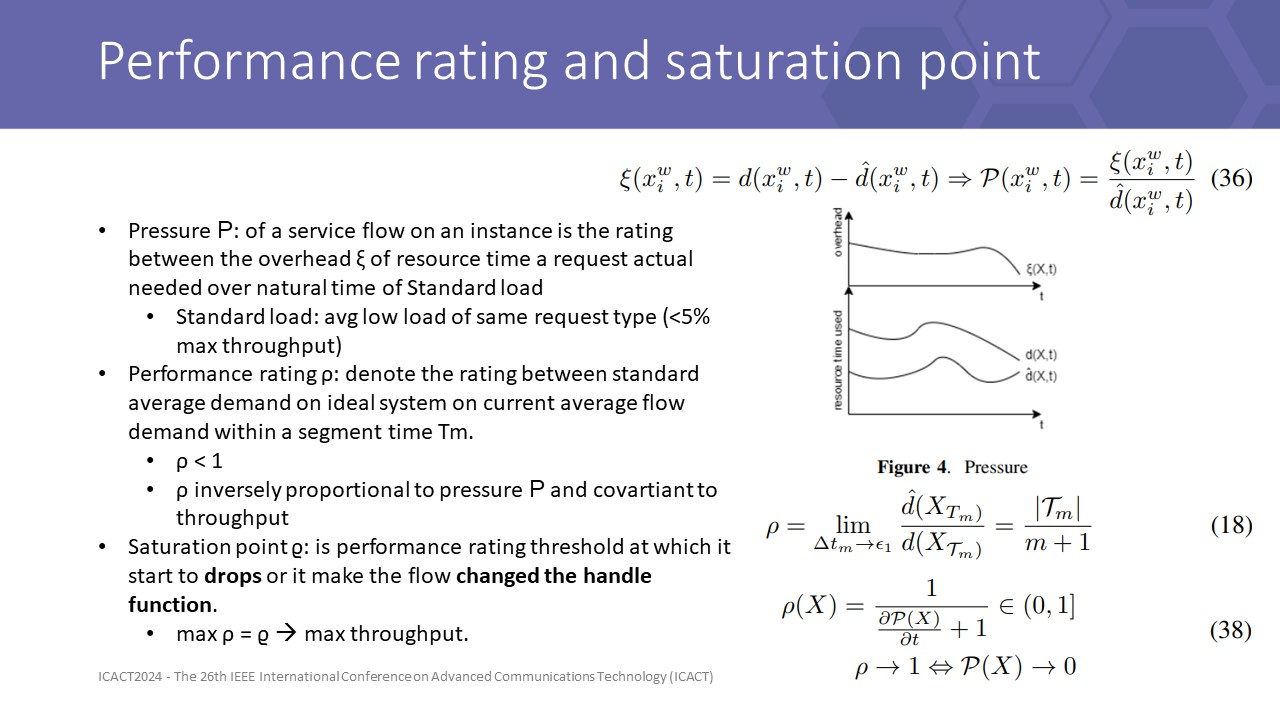 |
To optimize overall throughput, sensing 2 dimensions of the flow is not enough.
.
algorithm must control the flow to flood the weakest layer near the saturation point to archive the highest throughputthis guideline came from a Corollary when modeling the pressure of the flow on each instance, it said that if the performance rating gains maximum value at the saturation point
this is true because performance rating is covariant to throughput over equation (18) but it is not gaining forever until it reaches saturation point.
The demand for time to process increased when concurrency increased while opening more throughput. At the saturation point, the resistant force of pressure concurrently greater than the effective throughput makes the performance rating start to decrease.
|
|
ICACT20240417 Slide.16
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
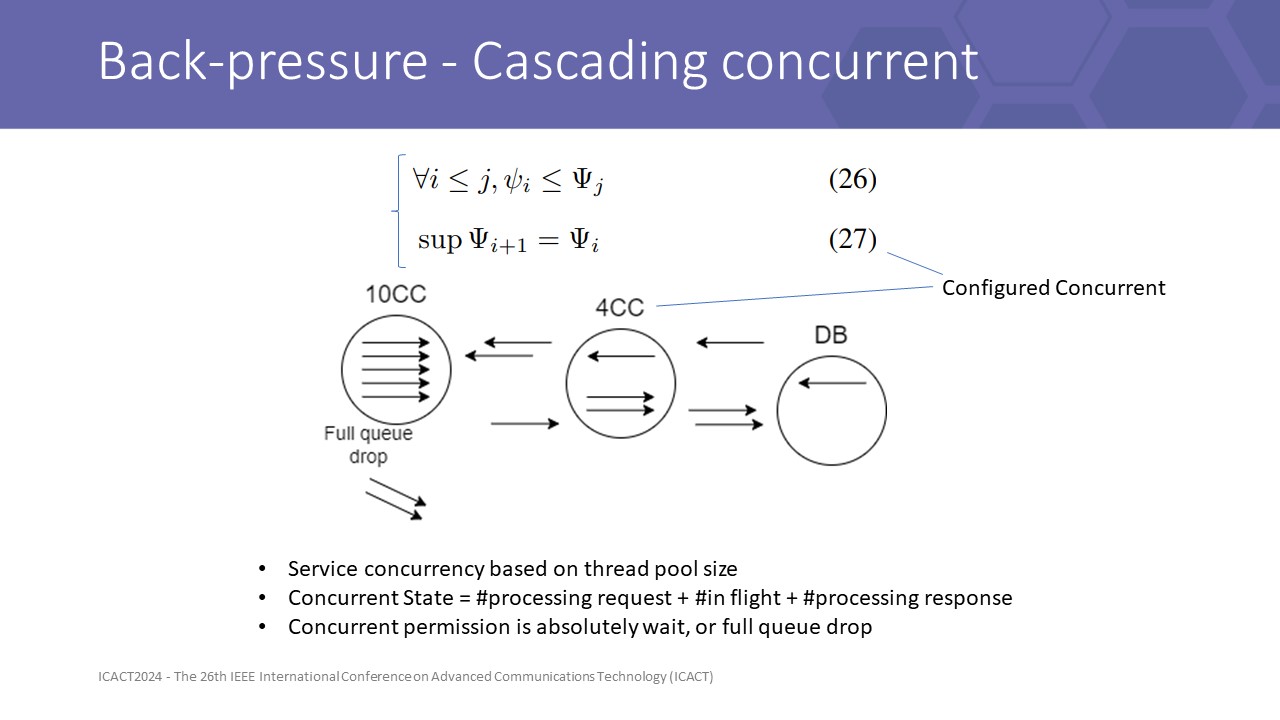 |
And yet some other formulas conclude that in asynchronous flow, if a routing algorithm can sense back pressure and well control the flow following it, then it can propagate the concurrent information to the previous layer, hence to the head of the system.
Because concurrent wait is an absolute wait, by 2 dimensions of a flow, if we only control or reduce the configured concurrent, hence we can reduce the thought too. forwarding flow needs to wait more for backward flow to release concurrent slot.
Therefore we can create a backpressure algorithm with only 1 control mechanism based on cascading concurrent value.
|
|
ICACT20240417 Slide.15
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
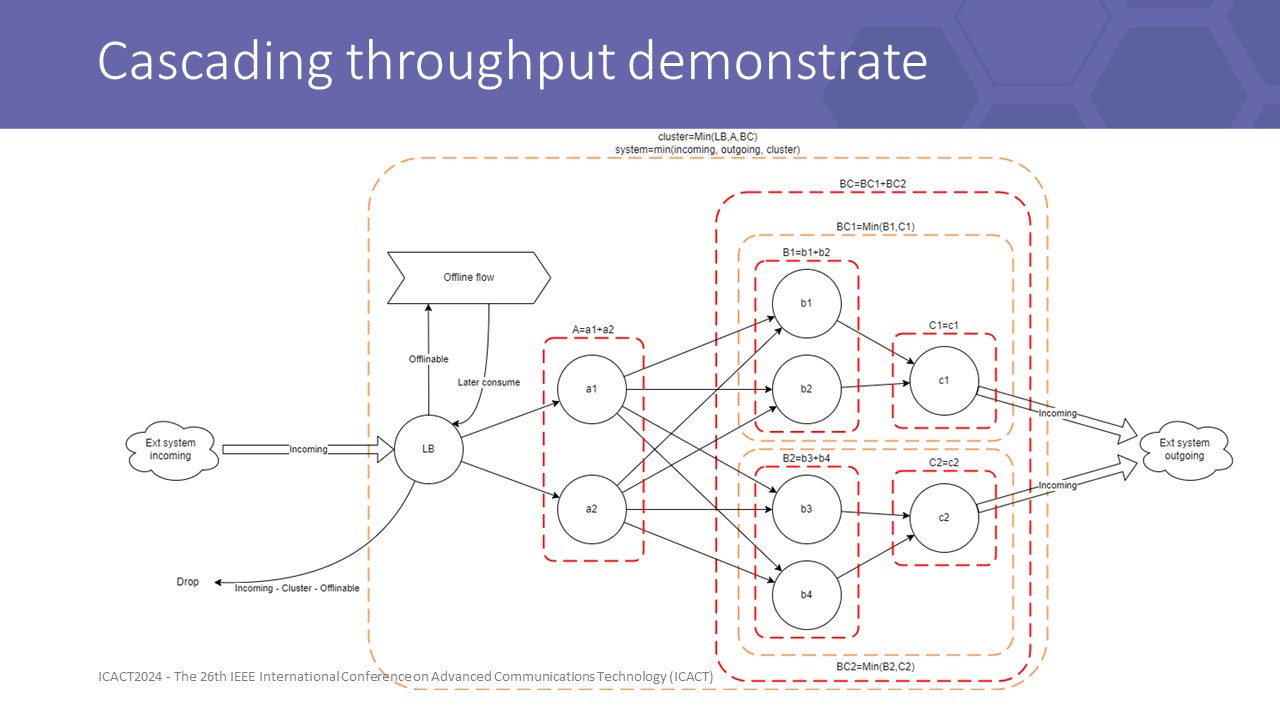 |
this figure shows how capacity is summed up over layers
with each isolated layer, the capacity is the sum capacity of all instances. with a chain of layers, the capacity is slowest layer
|
|
ICACT20240417 Slide.14
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
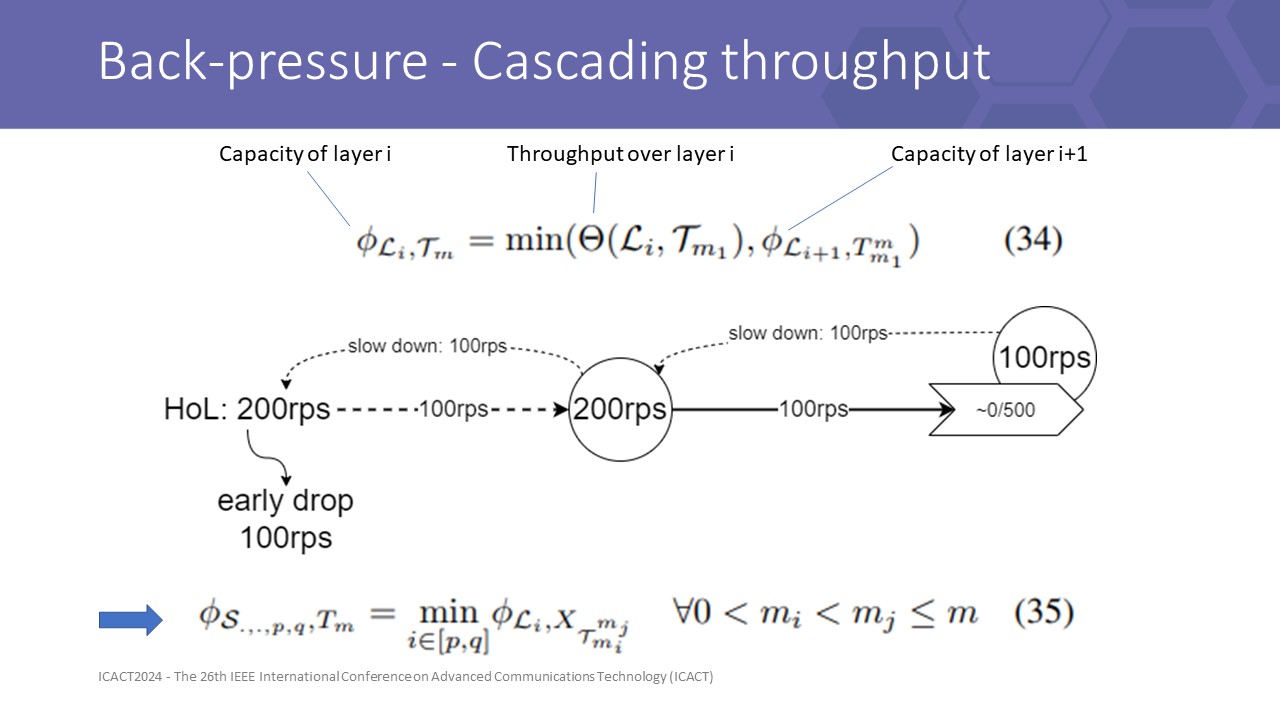 |
We proved some formulas to led to a conclude that in asynchronous API flow in mesh services, if a routing algorithm can sense back pressure and well control the flow following it, then it can propagate the throughput information to the previous layer, hence to the head of the system.
Then an important consequence is equation (35) maximum throughput of a system is the throughput of slowest layer so that we can identify the system capacity at the gateway then make an early drop decision to maintain the maximum throughput of the system
|
|
ICACT20240417 Slide.13
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
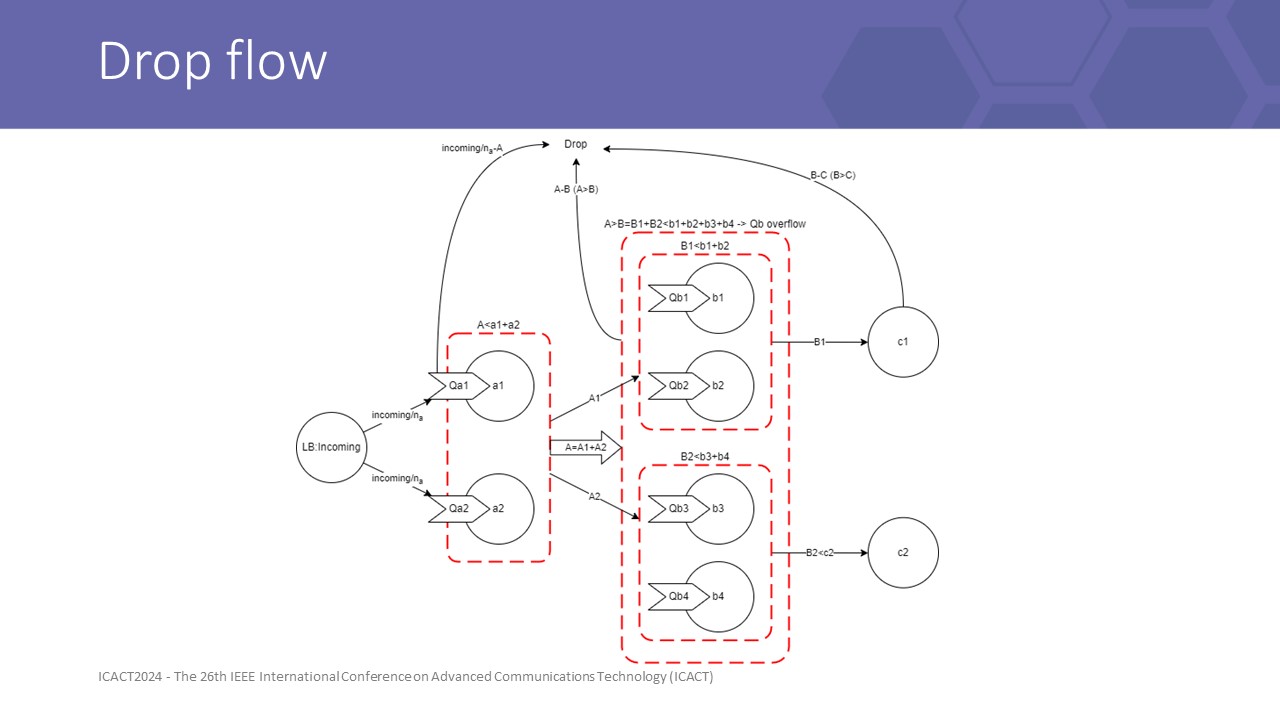 |
Drop flow can occur at any layer, especially with front pressure that layers have different capacity
When a drop occurs at any lower layer of the system, it wastes all computing power of front-line layers, and the user must wait all timeout deadlines to know their request has been denied
|
|
ICACT20240417 Slide.12
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The idea of backpressure comes from the idea about data fluid flow in the system like water flow in a pipe.
Each piece of the pipe is a service, with a different diameter, scaled by the concurrency level with other API flows.
flow comes with 2 natural dimensions: speed and bandwidth, or in API language, we call that throughput and the number of concurrent in-flight message
Then a back-pressure route strategy must control this 2 information along the API path, which means it can propagate, sense for it, and leverage it to control the speed of the flow
|
|
ICACT20240417 Slide.11
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Up next, we will bring you a brief illustration of backpressure model and algorithms
|
|
ICACT20240417 Slide.10
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
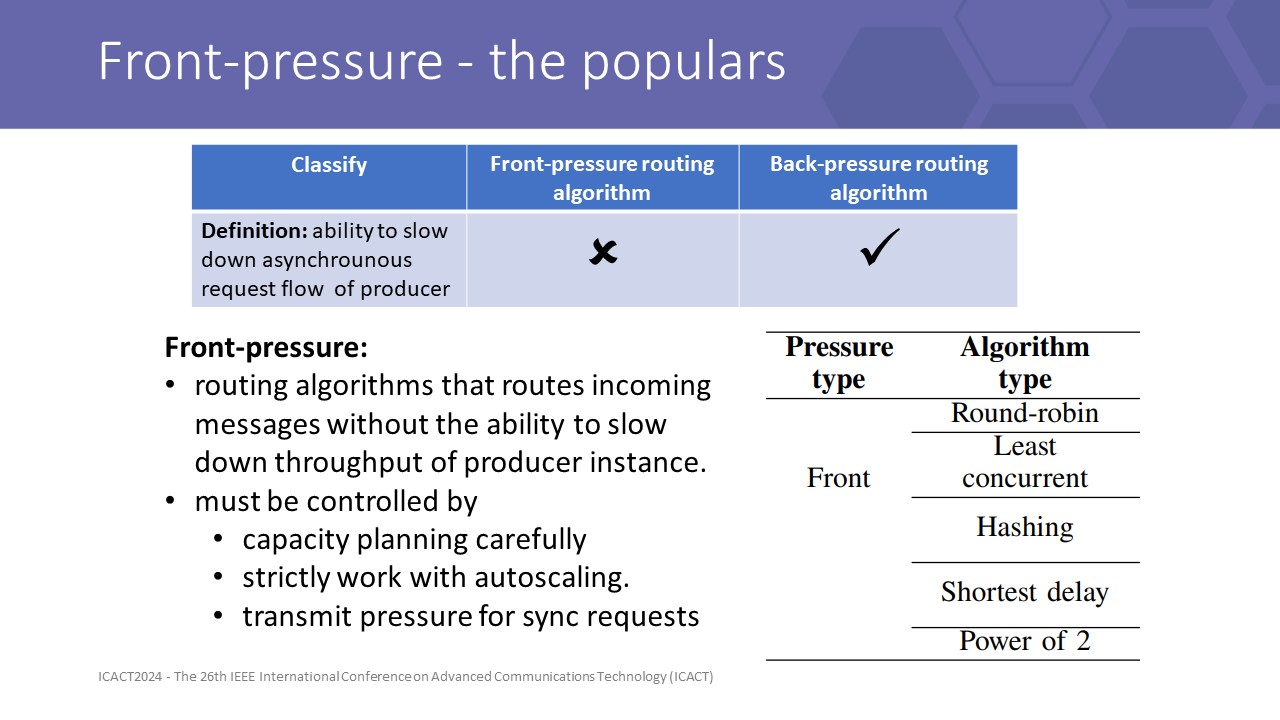 |
As we defined, front pressure is algo that cannot slow down or we may say cannot control the asynchronous flow, it just simply choose the destination and send
besides, back pressure algorithms can
Therefore most popular strategies are both front-pressureFront pressure can be used safely with sync requests or blocking actions, this helps client lock the resource that are calling at server and then slow down the process speed of the client
But locking is not an efficiency action, it will lock more than just the resources it needs.
So we need a backpressure strategy with some constraints to design algorithms
|
|
ICACT20240417 Slide.09
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
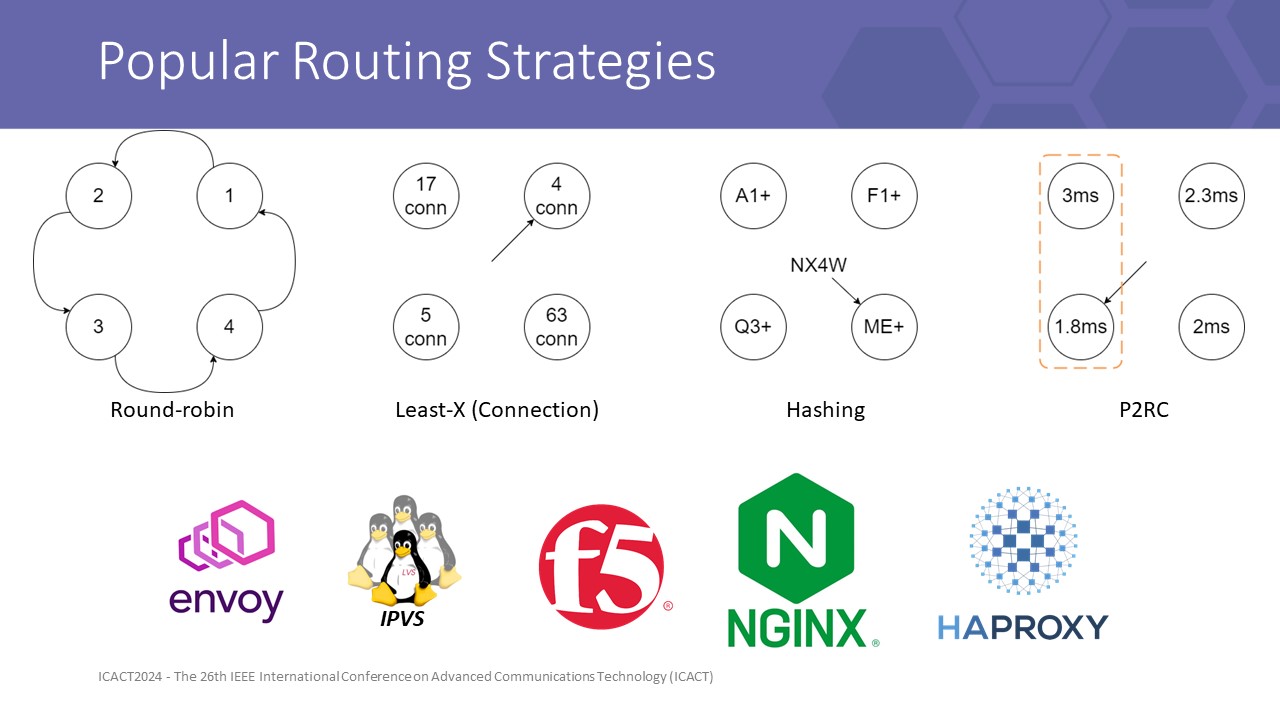 |
Some well-known algorithms in switching known in Envoy, F5 load balancer, IPVS, Nginx, and HAProxy are popular methods like Round-robin, Least connection, Destination or Source hashing, and Shortest delay.
However, HAProxy showed in a public test that P2R in action is not as good as RR, least connection, random, and using external LB.
This narrows our study to compare the effectiveness of complex back-pressure algorithms with simple algorithms such as least-X, RR only
|
|
ICACT20240417 Slide.08
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
continue the story
on peer-to-peer connection, in order not to lock unnecessary resources to obtain high performance, we used asynchronous requests but asynchronous is only responsible for the sending process, after firing the message, it forgets and listens to the response from the peer to trigger callback actions whenever it came back.
if the peer is implemented with a queue, it is fulfilled then drop the overflow message. The underlayer usually runs at full load, so a stream of steady bad latency KPI response that we earned.if the peer is not implemented with a queue, it is flooded and then degraded.
Therefore the response time increases with less throughput we earnedThis asynchronous sending mechanism cuts the pressure conjunction, making the client unable to know the server's healthy signal to refrain outgoing traffic.
Therefore we need a cascading method to transmit this lost pressure information back to the client to control the sending process.
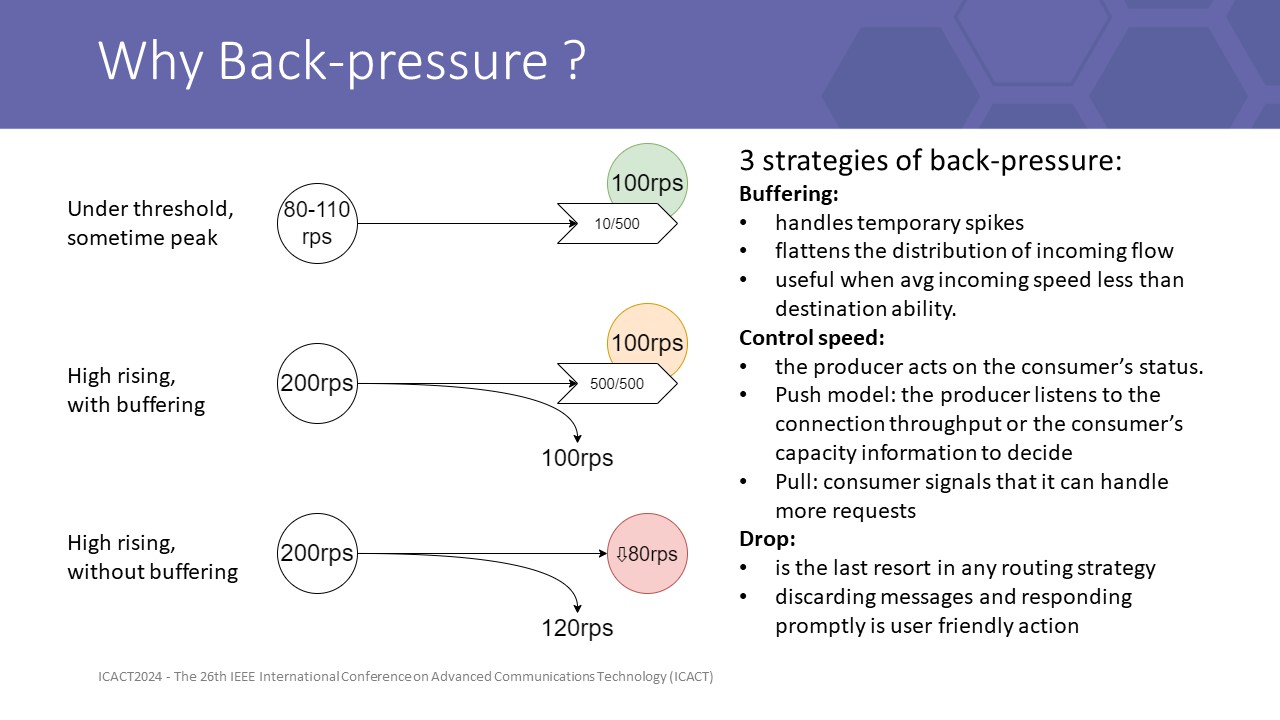
so that is the work of Back-pressure strategies. they sense the high-pressure flow then avoid routing to it or tell the producer to refrain from the speed Back pressure is useful when handling the case where the input rate is greater than the system can handle. In that case, Back-pressure must maintain the highest throughput of best (acceptable) quality, in asynchronous mode of course.
3 basic strategies of backpressure are buffering, drop, and control speed. a good back pressure strategy must well control this 3 actions in real timeAs we all know buffering is just a temporary solution to flatten short peaks, if incoming speed is high rising, no queue can save us due to Little’s Laws, and we must come to the last choice, drop.The last one is controlling the producer speed, this is what we target for designing our ILB.
Without flow control, to keep the load under the overload threshold, we usually need to plan large redundant capacity, and keep the system on even with the resources planned for the next 5-year growth. Furthermore, concurrency makes us maintain system utilization usually under 60% to archive stable URLLC KPI in core businesses, this 40% gap is a big waste.
|
|
ICACT20240417 Slide.07
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
After a while of searching around, turns out, that an old school approach like connection lib has shown its greatly effective in this extremely low latency problem.
This architecture was famous and implemented within 3 open-source libraries: Uber Hyperbahn [13], Java Maven library Netflix Ribbon [14], and Meta ServiceRouter Lib (SRLib) [15].
The Lib connection approach mainly serves the need for extremely low latency connection and self-managed data flow. It creates direct connections between peers, on the layer 4 network connection and manages each inside the internal client load balancing (ILB) module embedded in each application.
This approach required us to care more about engineering aspects of a connection like lag, misconfigured, and incidents, ... however, also brought us the raw latency of the low-level network.
The ILB can be used independently or it has interfaces to interact with the centralized control plane. ILB gives us a platform to observe and control peer connections. It gives us the ability to imply full-time protection for the system and customize utilities for our use cases.
The cloud infrastructure in terms of provisioning, scale-up, scale down to adapt to user demand, delivers very late results in comparison to system demand changes. Meanwhile, some instances may overload, leak to death, and lead to a chain of catastrophe while waiting for resources to be provisioned.
the principle of ILB is simple, try to deliver the best decision with as much local information as possible. It controls the flow per-hop by per-flow on a p2p basis and acts immediately on each request it sends.
ILB solved the latency problem by removing hops of external proxy and sidecar, bringing the ability to be quick, continuous, and self-decidable in complex misinformation cases, and response to local factors without adding network delay.
One of the minor problems of ILB is that it increases computing overhead for flow control. But with an instance allocated with more than 2 vCPUs and less than 30kTPS, this is not a big problem.
The problem of lib connection from point of view of ILB connection lib is that all messages are equal, which means the lib can not use some dimensions to make decisions, like 1) latency and timing, Timeout is defined by business, 2) message Size, 3) API Destination or path
|
|
ICACT20240417 Slide.06
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Inverse to adding hop for managing, we implement the sidecar directly into a library that runs with the app.
as we all know, while we use connection libraries like java netty, python tornado, socketio, etc, we usually need to build a wrapper library that serves the need for creating clients, servers, and peer connections with some override attributes.
so that on the expansion of our netty wrapping library, we developed our Microchassis library which was the first basis for this connection lib approach
|
|
ICACT20240417 Slide.05
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
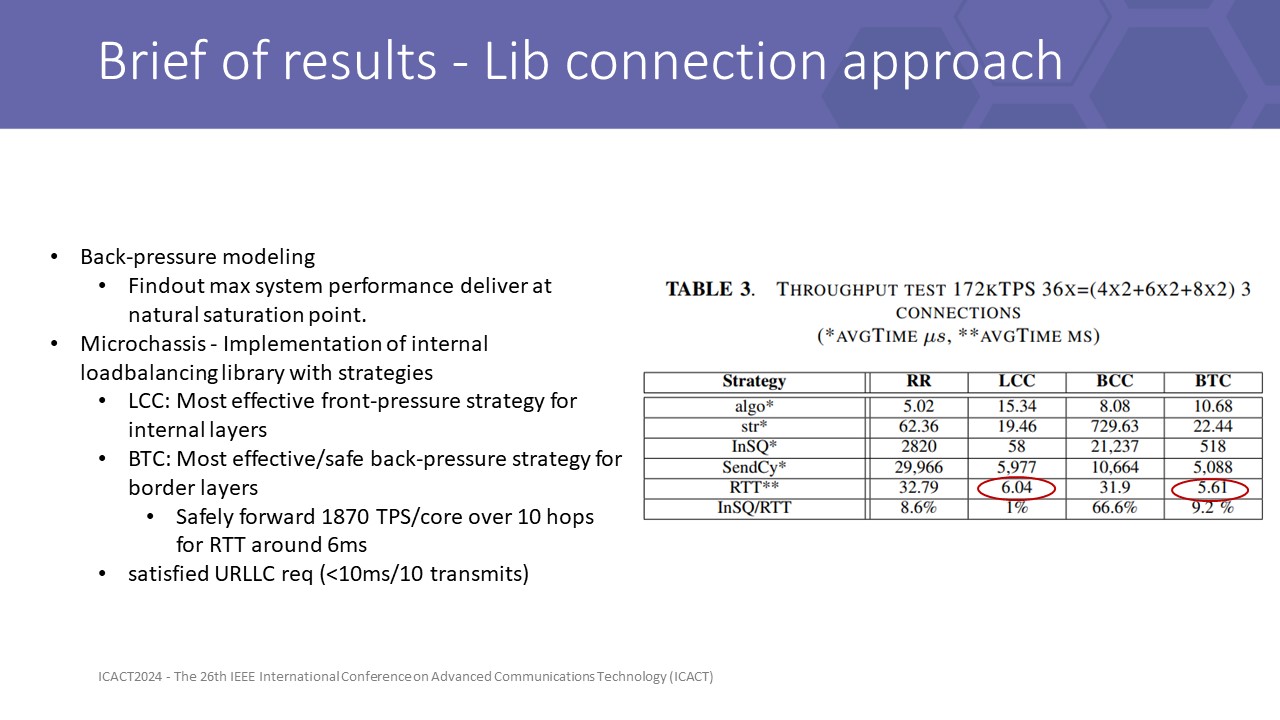 |
in summary, our research on back-pressure modeling gives us the most important improvement of system maximum throughput, in which if the back-pressure routing strategy respects this threshold, it can deliver the best latency as it was at a low throughput system.
Results on our testbed server output about 1870 safe forward 4KB messages per second on each core we assigned to the microchassis. All satisfy URLLC standards.
|
|
ICACT20240417 Slide.04
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
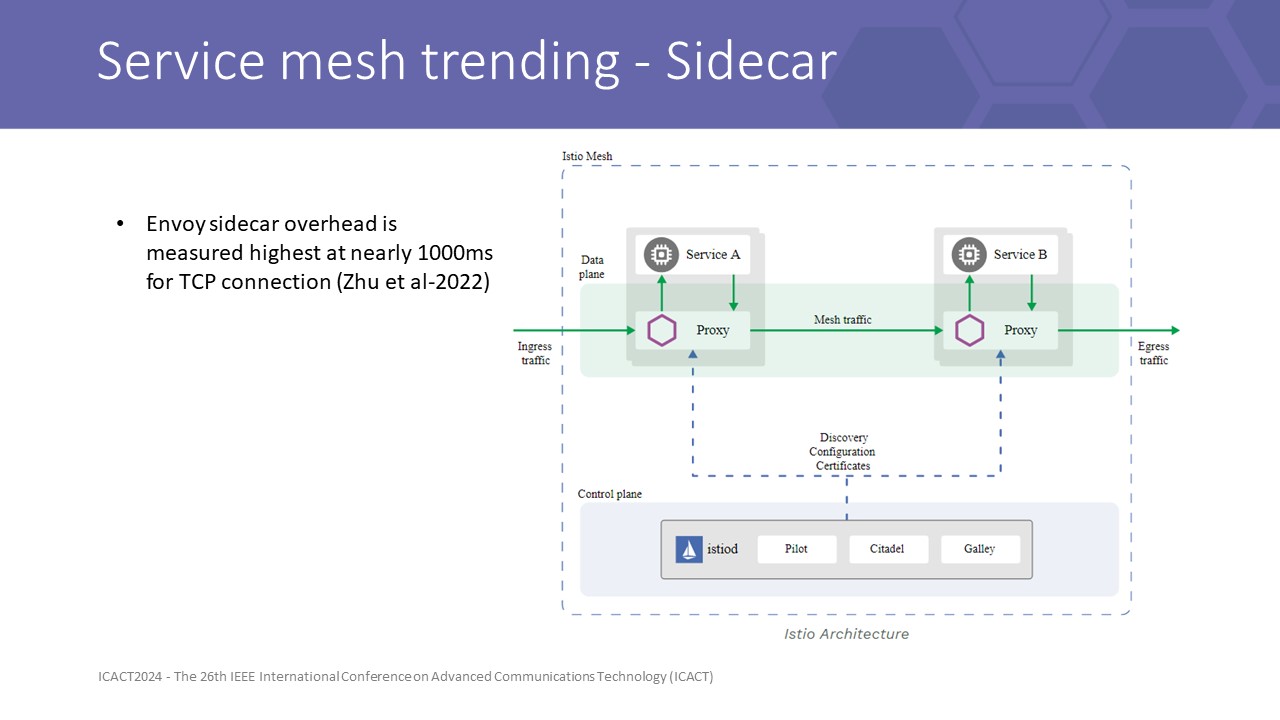 |
To the overview of recent service mesh trends, nowadays, Service mesh with an independent sidecar is favored for its flexible capability and cost-effectiveness in a variety of purposes with the ability to be transparent under network layers.
Here is the abstract architecture of the sidecar approach with an example of the most popular Istio control plan with the Envoy sidecar.
This architecture adds hops and management filters over the transmit way, the service mapping, service discovering, and routing logic are handled here at the sidecar. The application just needs to send to a specific port that maps to the next service layer to successfully deliver the messages.
This is great if the problem is not ultra-low latency. So this architecture, added a few to a hundred milliseconds to the round trip time each hop. This overhead latency was also studied in previous research, especially in the paper of Zhu et al. They announced a method to predict the overhead of latency when using a sidecar. The results show that it could add nearly 1000ms on average to direct TCP connection round trip time with disabled filter profiles. In gRPC mode, the number multiply 3 to 5 times.
This strongly reinforces our approach not to leverage sidecar connection to satisfy the URLLC requirements
|
|
ICACT20240417 Slide.03
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
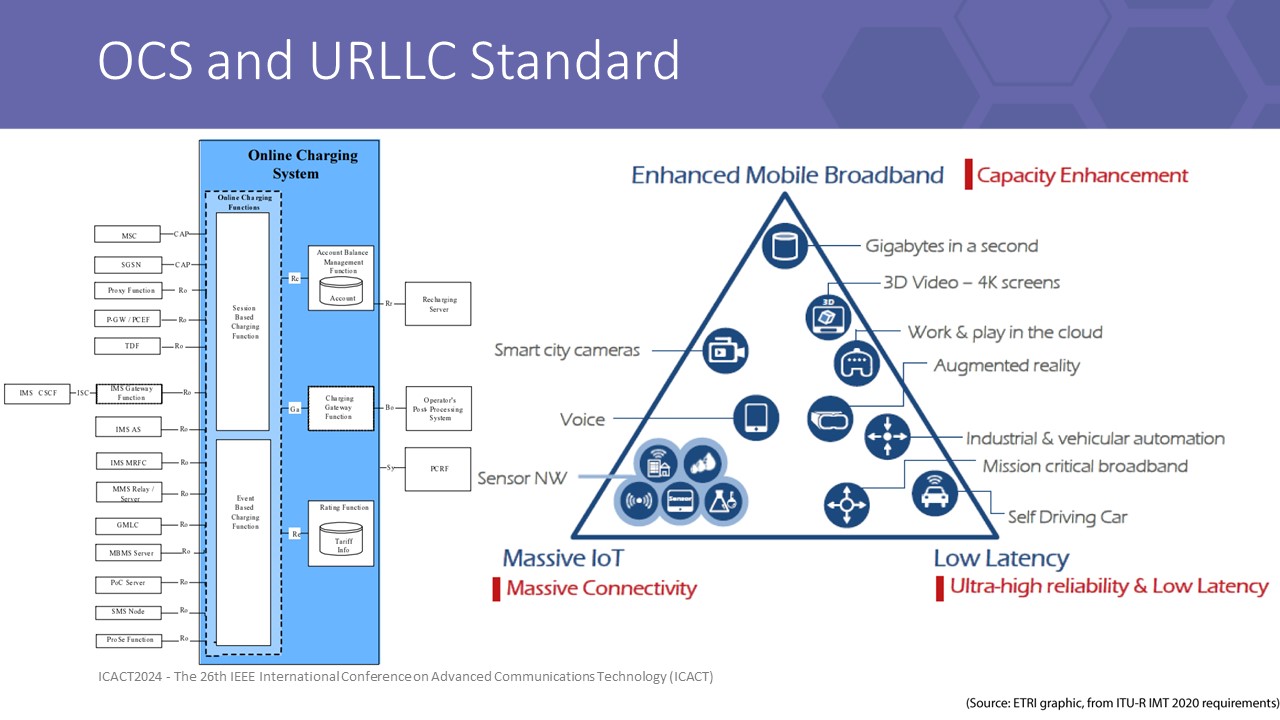 |
firstly we are Viettel corporate which is the greatest telco in VN. Our products span military and civilian equipment. In terms of that, our branch company, Viettel High Tech, is responsible for designing the Online charging system, which is the heart of telco services. Every usage action of customers is reflected in charging requests, which are around 100 million accounts and result in nearly 100k transactions per second peak.
this leads us to the class of mesh problem that can be linear scalable to give the end user the same response time at a large system scale.in terms of “the heart”, we are a core system that is behind many overlay infrastructure systems, therefore our product is set under very strict SLA and KPI.
More specifically, to achieve the ability to support 5G categories, the OCS needs to deliver latency that obeys the URLLC standard.
URLLC is a hard-to-archive KPI in 5G for software components, especially on the way to the cloud, where everything needs to be generalized and more slowly.
This urges us to renovate our lib connection underlying the core services app to deliver end-to-end acceptable latency at scale.
|
|
ICACT20240417 Slide.02
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In the introduction, we will show you the overview of the OCS system in telco.
|
|
ICACT20240417 Slide.01
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Our presentation covers 5 sections
introduction about the OCS system and the motivation for our research,
Related work and some related terminologies
then we will describe our model in the mesh problem
Next, we design tests and analyze some results
And finally are conclusions to have a better performance on low latency system
|
|
ICACT20240417 Slide.00
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Greetings everyone, we are Viettel High Technology engineers present here for our latest research result of our microservices mesh optimization
|









