 |
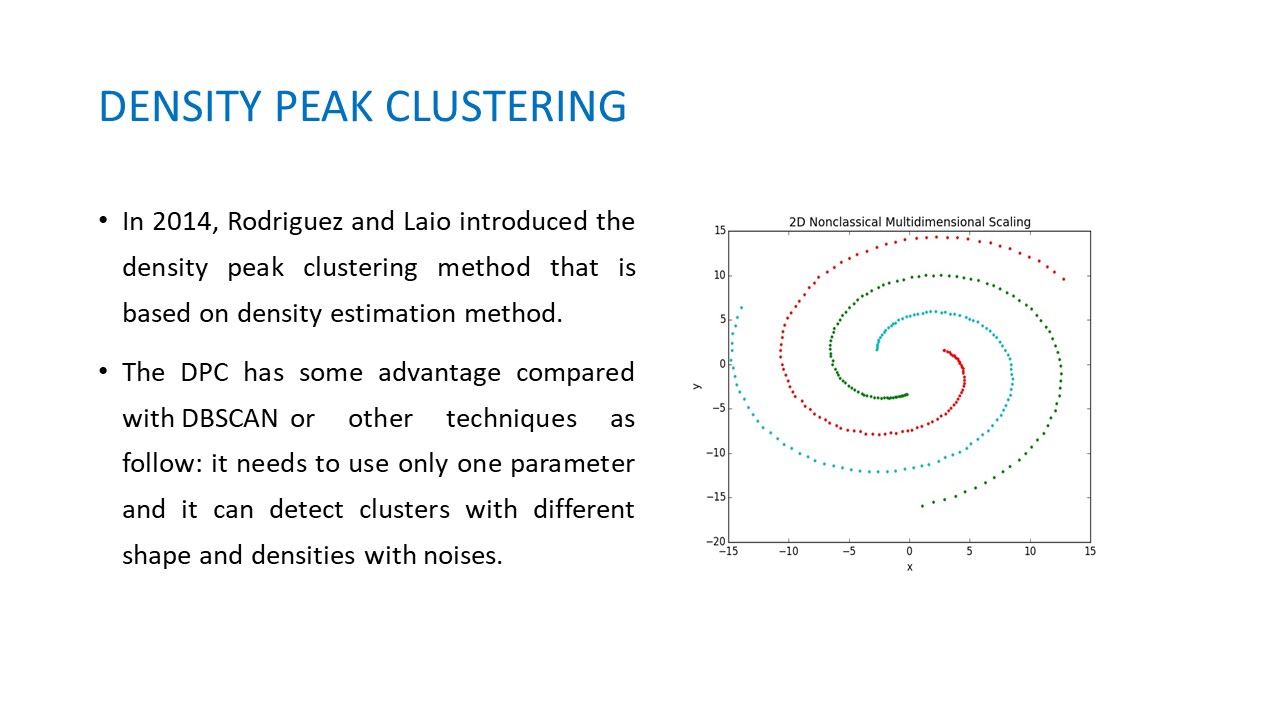
In general, clustering methods can be grouped in some kinds including partition methods, hierarchical methods, density based method and model based methods. Partition clustering aim to divide the data objects into k clusters using an objective function for optimizing. We can cite here some major algorithms such as K-means and Fuzzy C-Means. Hierarchical clustering (HC) algorithms usually organize data into a hierarchical structure according to the proximity matrix. The results of HC are usually depicted by a binary tree or dendrogram. From the organized dendrogram, we can decide which level of dendrogram may cut off to form the final clusters. The idea of density based clustering detects clusters by identifying those regions where each region is a dense group of points. DBSCAN and SNN are two methods based on the density estimation concept. Model-based techniques assume that the distribution of data fit a model mathematic, and the finding clusters are equal to an optimization process to fit between mathematic model and data distribution. In 2014, Rodriguez and Laio introduced the density peak clustering method that is based on density estimation method. The DPC has some advantage compared with DBSCAN or other techniques as follow: it needs to use only one parameter and it can detect clusters with different shape and densities with noises. |
 IEEE/ICACT20220068 Slide.04
[Big Slide]
IEEE/ICACT20220068 Slide.04
[Big Slide]