 |
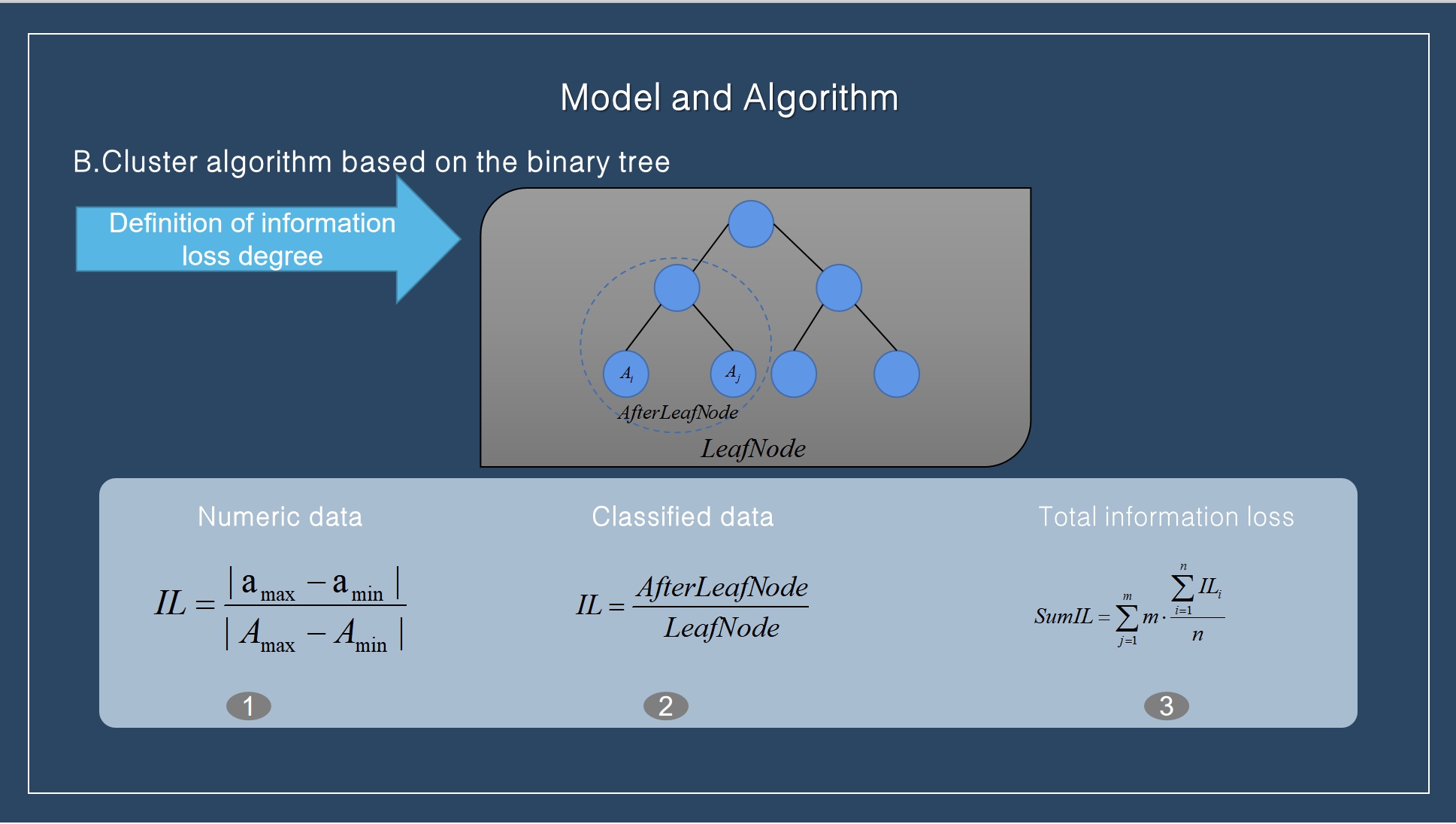
The principle of K-anonymity implementation is to generalize the QI attribute of the target identifier and protect the data on the basis of certain information loss, so that the attacker cannot identify it. The purpose of the data set after clustering is to make the similarity of the divided equivalence classes higher, thus reducing the loss of some k-anonymity information. Therefore, in order to measure the information loss degree of the method proposed in this paper more reasonably, according to the characteristics of different attribute types, the information loss after anonymity is calculated from numerical and sub-type attributes respectively, and the calculation methods are (1) and (2). The total information loss calculation method is shown in (3). |
 IEEE/ICACT20230212 Slide.10
[Big Slide]
IEEE/ICACT20230212 Slide.10
[Big Slide]