 |
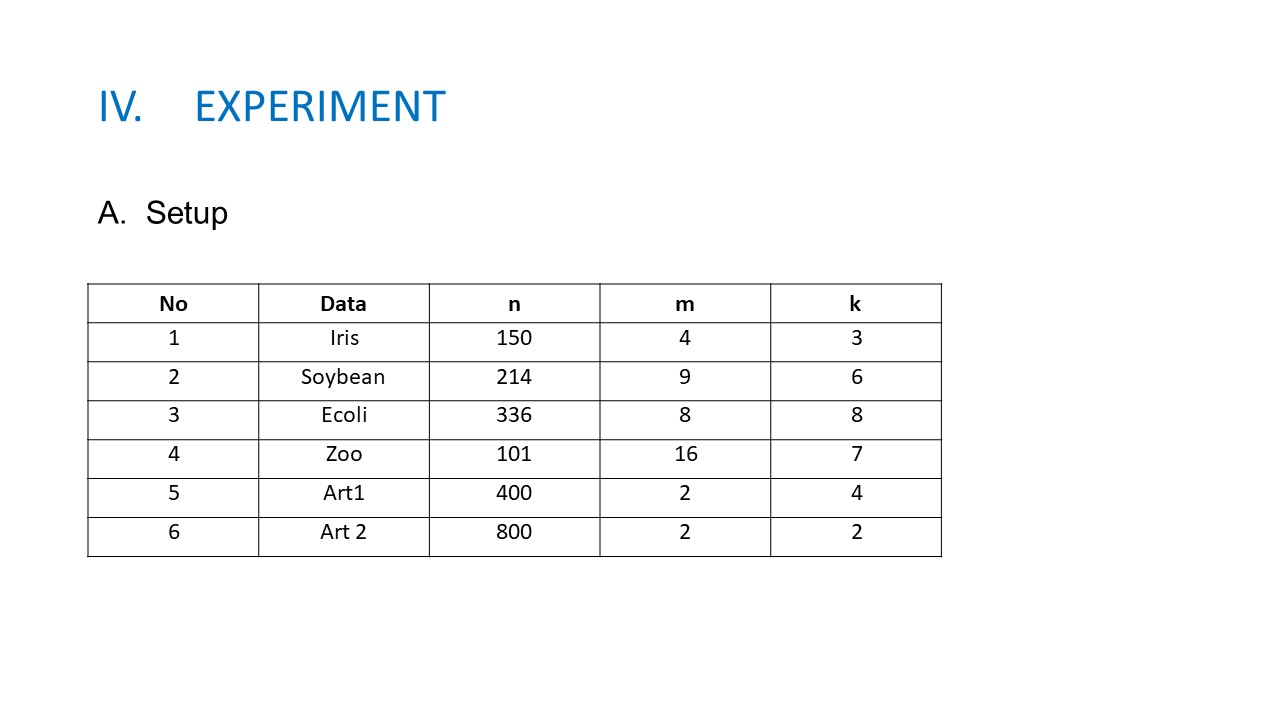
Part 4 EXPERIMENTS. A. Experimental setup To evaluate our new algorithm, we have used four data sets from UCI machine learning and two data sets are generated follow the Gaussian distribution. The details of these data sets are presented in Table 1, in which n, m, and k respectively are the number of data points, the number of features, and the number of clusters. To evaluate the clustering results we have used the Rand Index (RI) measure, which is widely used for this purpose in different researches. The RI calculates the agreement between the true partition (P1) and the output partition (P2) of each data set. To compare two partitions P1 and P2, let u be the number of decisions where xi and xj are in the same cluster in both P1 and P2. Let v be the number of decisions, where the two points are put in different clusters in both P1 and P2.
The value of RI is in the interval [0ˇ¦1]; RI = 1 when the clustering result corresponds to the ground truth or user expectation. In our experimentation, we use the Rand Index in percentage. The higher the RI, the better the result of clustering. |
 IEEE/ICACT20220068 Slide.12
[Big Slide]
IEEE/ICACT20220068 Slide.12
[Big Slide]