 |
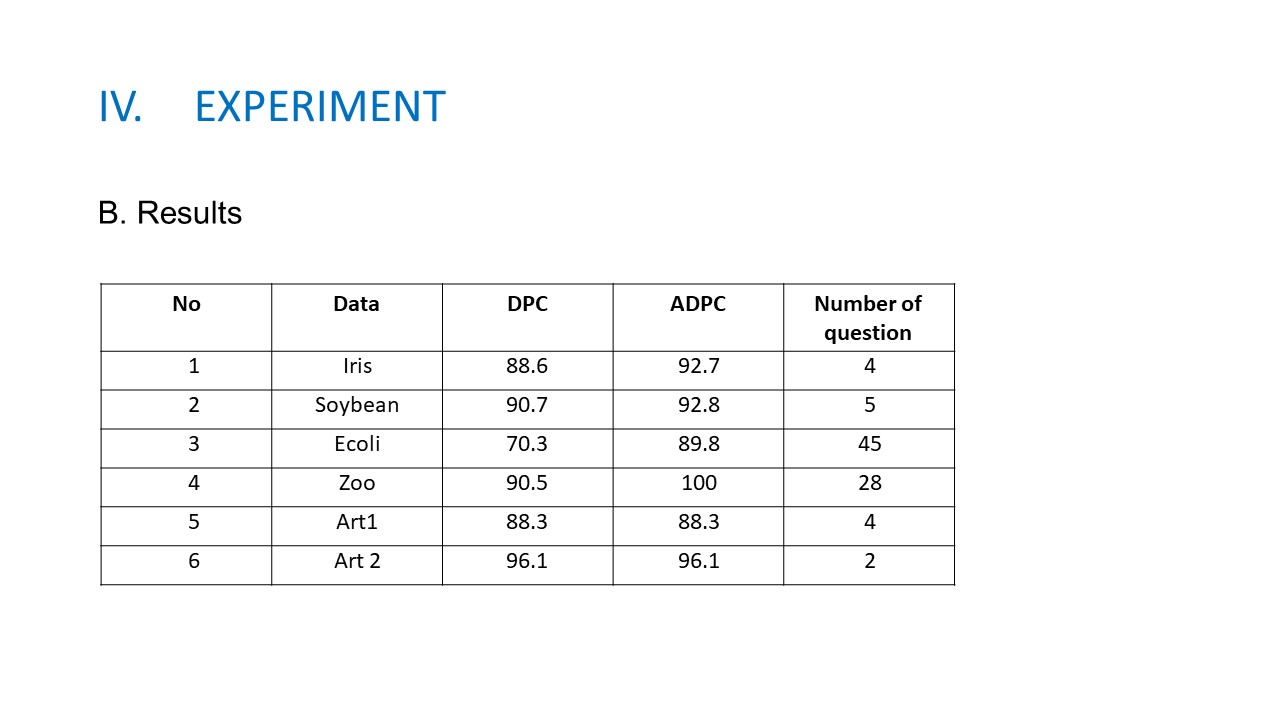
B. Experiment results. Table 2 presents the Rand Index measure obtained by two methods DPC and ADPC. From the table, we can see that, with some questions proposed for users, we can collect exactly the number of clusters and hence the quality of clustering process had been improved. Some details explanations will be made as follows. For the Iris data set, it has three clusters in which two clusters are overlaps, so DPC can not detect exactly the number of clusters as mentioned in the figure 3. In contrary, by soliciting label from users for data points with high density, we can collect the cluster centers and the clustering results will be improved. For Soybean data set, the explanation is similar to Iris, DPC cannot detect four clusters, using ADPC, we can detect four cluster centers after five questions and the result is enhanced. For Ecoli data set, it is an imbalanced data with cluster size from 2 to 142, so we need 45 questions to collects the labels for cluster centers and ADPC obtained the RI with 89.8% while DPC cannot detect the number of clusters and ADPC obtained the good results compared with DPC. The results can be explained by the fact that real data sets always have complex distribution and the peak may appear in many regions in each cluster. Using decision graph to identify the cluster centers may have some troubles. Figure 4 shows the decision graph of Ecoli data set. It can be seen from the figure that it is not easy to choose the good cluster centers without using domain experts. |
 IEEE/ICACT20220068 Slide.13
[Big Slide]
IEEE/ICACT20220068 Slide.13
[Big Slide]