 |
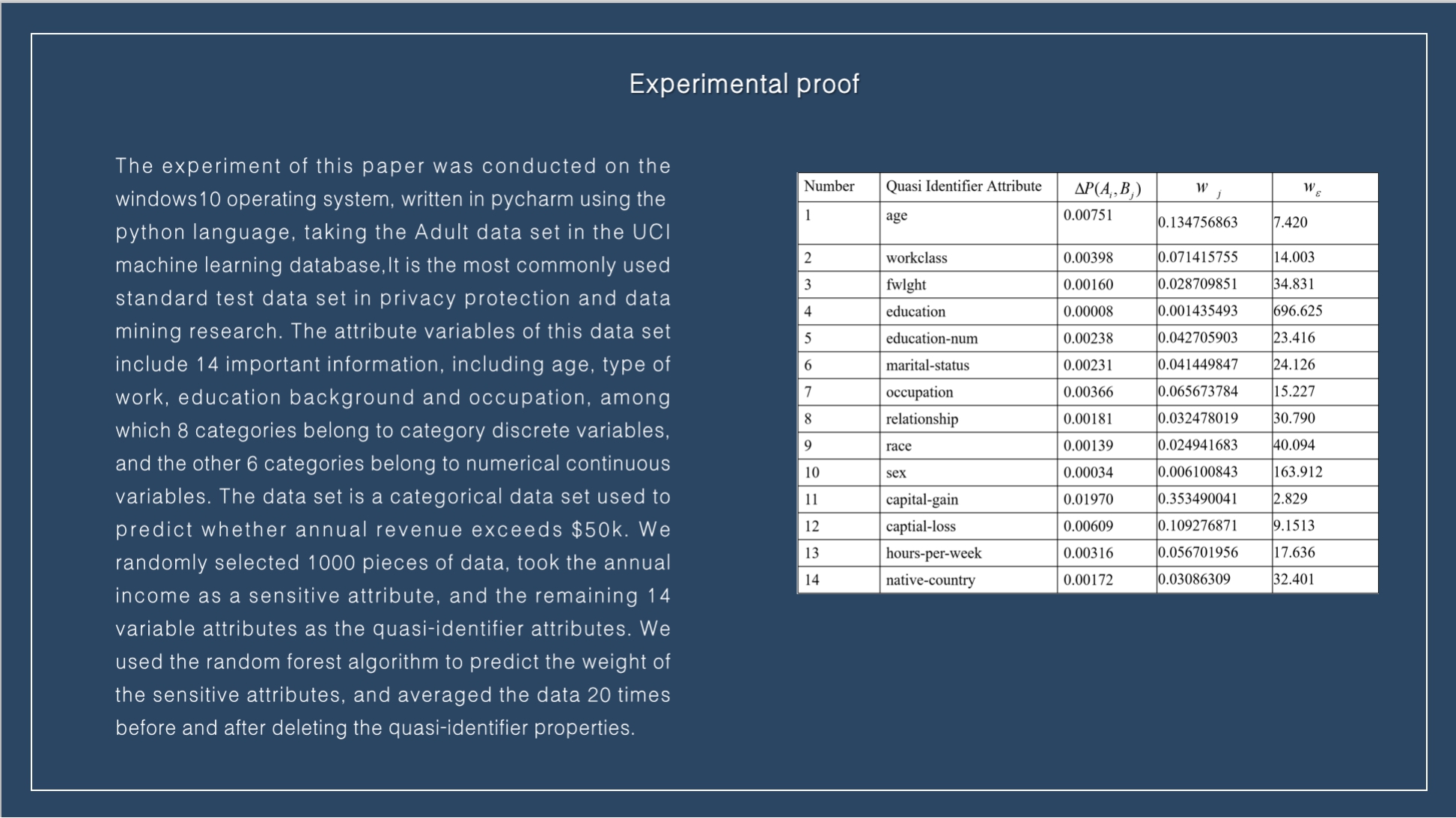
The experiment of this paper was conducted on the windows10 operating system, written in pycharm using the python language, taking the Adult data set in the UCI machine learning database,It is the most commonly used standard test data set in privacy protection and data mining research. The attribute variables of this data set include 14 important information, including age, type of work, education background and occupation, among which 8 categories belong to category discrete variables, and the other 6 categories belong to numerical continuous variables. The data set is a categorical data set used to predict whether annual revenue exceeds $50k. We randomly selected 1000 pieces of data, took the annual income as a sensitive attribute, and the remaining 14 variable attributes as the quasi-identifier attributes. We used the random forest algorithm to predict the weight of the sensitive attributes, and averaged the data 20 times before and after deleting the quasi-identifier properties |
 IEEE/ICACT20230212 Slide.14
[Big Slide]
IEEE/ICACT20230212 Slide.14
[Big Slide]