 ICACT20230136 Slide.17
[Big slide for presentation]
ICACT20230136 Slide.17
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! Click!! |
 |
That's all for my report. Thank you for your comments.
|
|
ICACT20230136 Slide.16
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
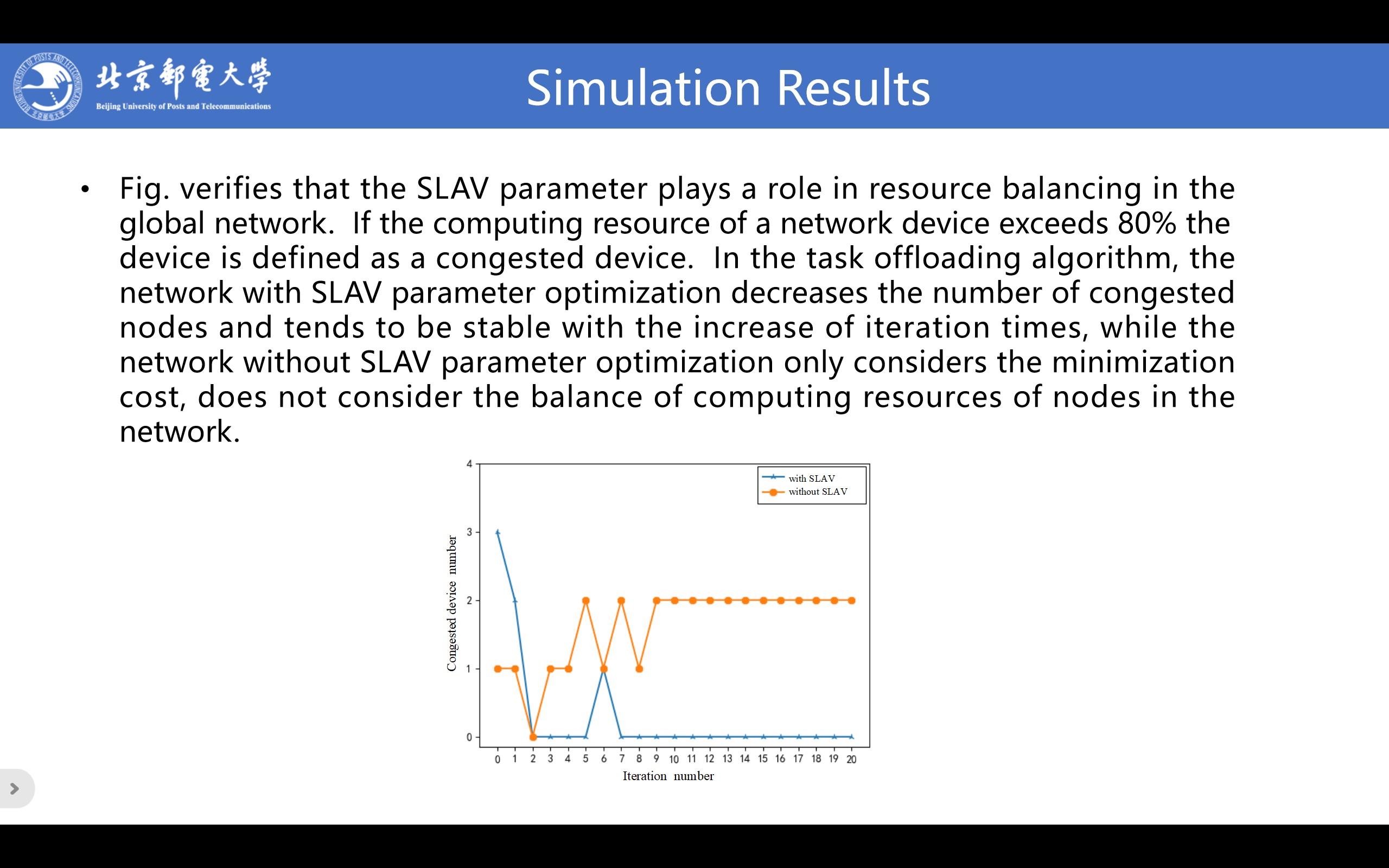 |
In addition, Fig. verifies that the SLAV parameter plays a role in resource balancing in the global network. If the computing resource of a network device exceeds 80% the device is defined as a congested device. In the task offloading algorithm, the network with SLAV parameter optimization decreases the number of congested nodes and tends to be stable with the increase of iteration times, while the network without SLAV parameter optimization only considers the minimization cost, does not consider the balance of computing resources of nodes in the network.
|
|
ICACT20230136 Slide.15
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
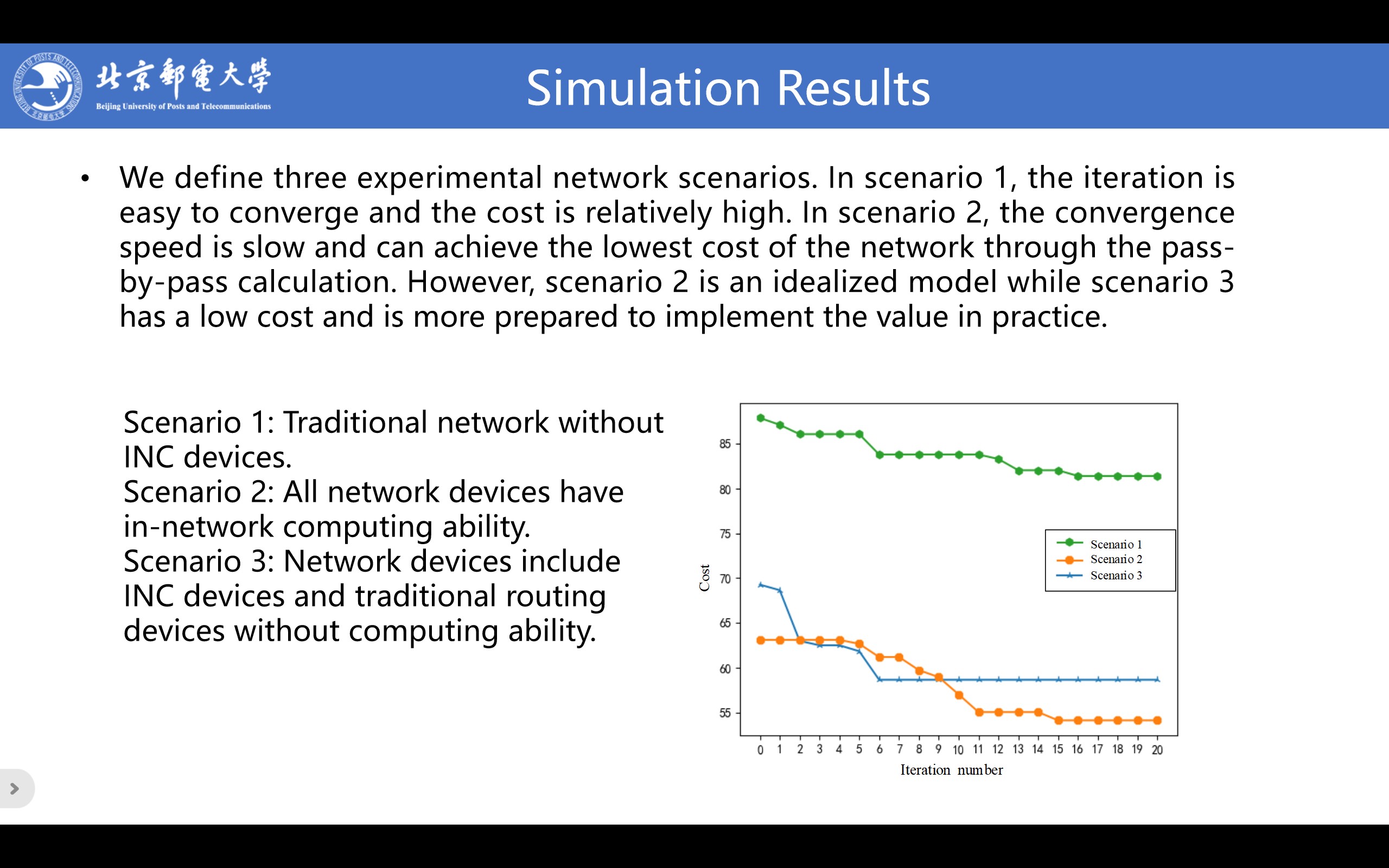 |
We define three experimental network scenarios. Scenario 1: Traditional network without INC devices. Scenario 2: All network devices have in-network computing ability. Scenario 3: Network devices include INC devices and traditional routing devices without computing ability. We conducted experiments in three network scenarios. It can be seen that in scenario 1, subtasks can only be offloaded in MEC and cloud with computing ability. The iteration is easy to converge and the cost is relatively high. In scenario 2, the convergence speed is slow and there are no traditional routing devices in scenario 2, so INC devices can achieve the lowest cost of the network through the pass-by-pass calculation. However, scenario 2 is an idealized model while scenario 3 has a low cost and is more prepared to implement the value in practice.
|
|
ICACT20230136 Slide.14
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
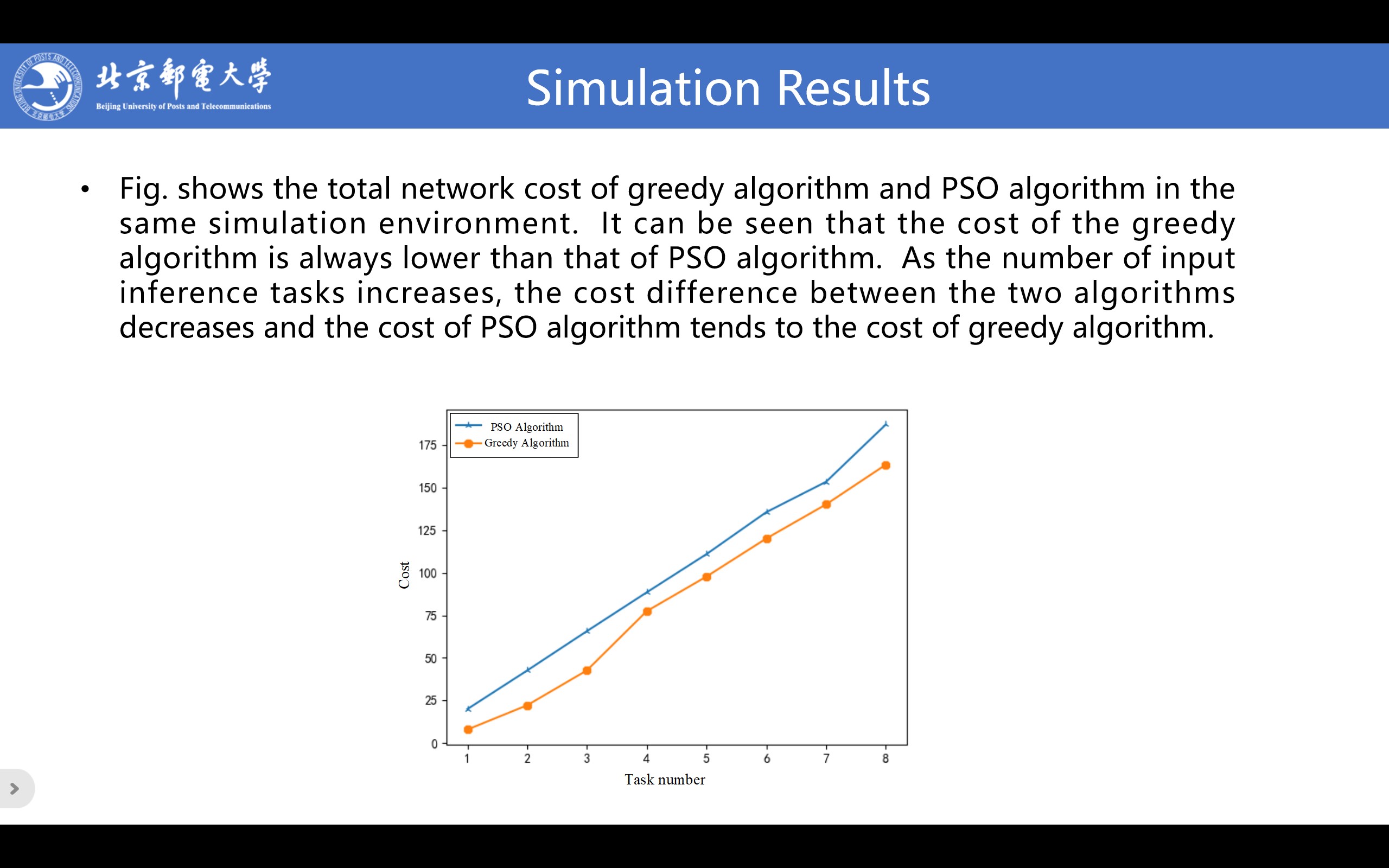 |
Fig. shows the total network cost of greedy algorithm and PSO algorithm in the same simulation environment. It can be seen that the cost of the greedy algorithm is always lower than that of PSO algorithm. As the number of input inference tasks increases, the cost difference between the two algorithms decreases and the cost of PSO algorithm tends to the cost of greedy algorithm.
|
|
ICACT20230136 Slide.13
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
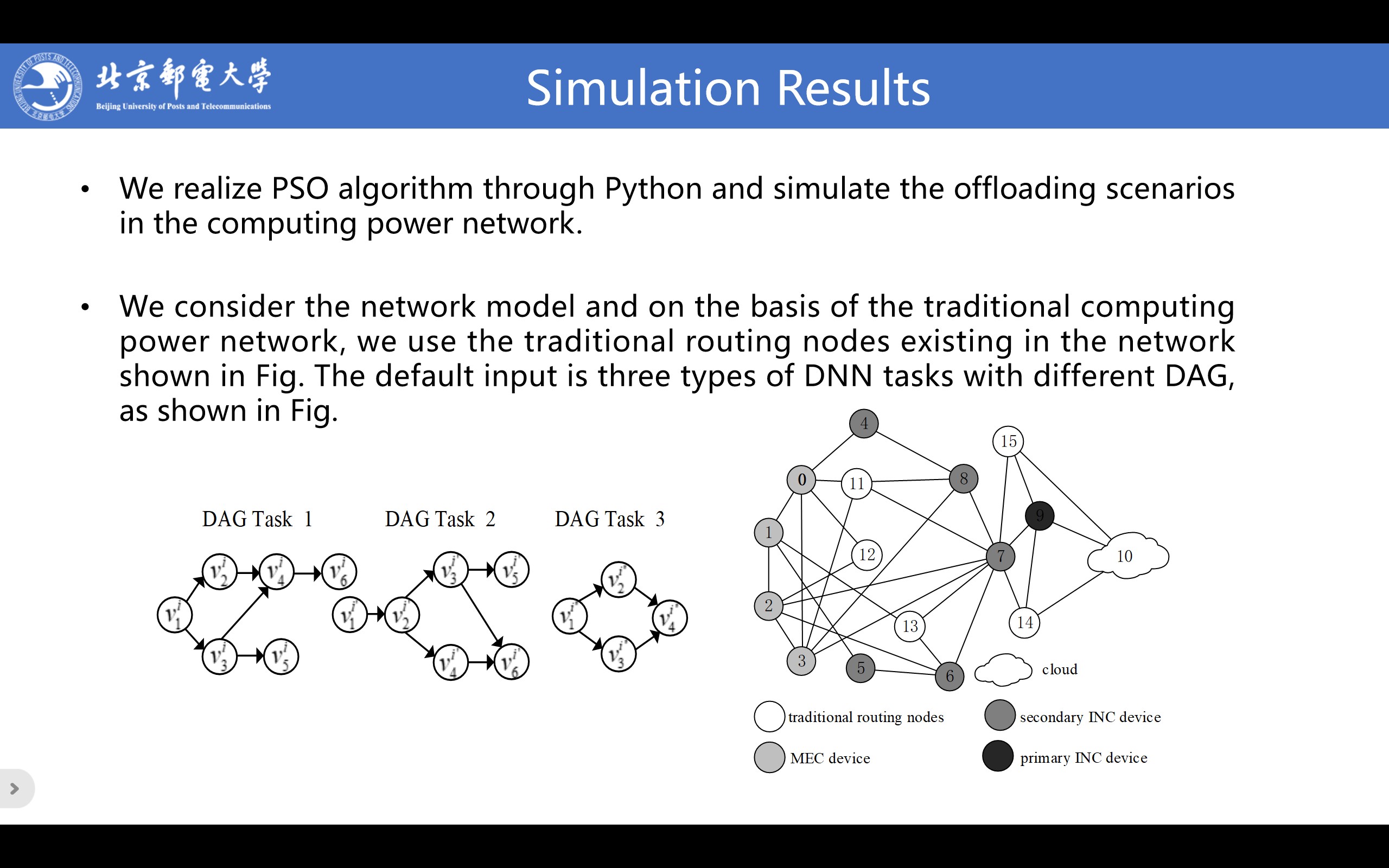 |
We realize PSO algorithm through Python and simulate the offloading scenarios in the computing power network.
In the network topology, parameters such as links are set randomly. In this simulation, the link is set to 100Mbps. We set the computing resource to 2 GHz for each MEC device, to 5 GHz for each primary INC device and to 3 GHz for each secondary INC device. The default unit computation cost of node is set to 1. For cloud, we set the computing resource to 10 GHz and the default unit computation cost to 1.12. The proportion of remaining computing resources is randomized to (0.6,0.8).
The default input is three types of DNN tasks with different DAG. For inference task i, service access is randomly performed from four arbitrary edge nodes and the task deadline is randomized to (20,75) seconds. The transmission ratio of each subtask is set to (0.01,0.05) and the amount of transmitted data is randomized to (1.5, 2) Mbit. By default, the distance between subtasks is the number of hops between offloaded nodes and the unit of transmission is set to 0.5. In addition, we set the inertia weight ω to 0.08 and the speed constraint V_max to 10. We set the learning factor c_1 to 0.2 and c_2 0.5. We set the swarm size to 10 and the number of iterations to 20. During the evaluation process, the value of each parameter may change.
|
|
ICACT20230136 Slide.12
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The fourth part is the simulation results.
|
|
ICACT20230136 Slide.11
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Particle swarm optimization: PSO algorithm is a stochastic optimization technique. Its basic idea is to find the optimal solution through cooperation and information sharing among individuals in the swarm.
Step 1: Initialize the swarm. We give the initial velocity vector and initial position vector of the particle. We also give the swarm size and set various parameters.
Step 2: Calculate the fitness value. We calculate the fitness value of the particle and save it. We compare it with the historical optimum fitness value of the particle, save the smaller value as the optimum fitness value.
Step 3: Find the global optimum fitness value of the swarm. The smallest optimum fitness value of the swarm is used as the global optimum fitness value and every particle preserves it.
Step 4: Update the particle velocity and position. Each particle updates its velocity and position in the iteration.
Step 5: Check whether the algorithm is complete. When the number of iterations is less than the maximum number of iterations, repeat step 2, step 3 and step 4. Otherwise, the iteration terminates.
|
|
ICACT20230136 Slide.10
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In this section, the DNN task offloading strategy based on PSO algorithm are introduced. First, the task is input by the MEC device and the subtasks of the task are sorted. Then, PSO algorithm is used to constantly update the offloading position. When convergence is achieved, the optimal offloading position is obtained.
Subtask sorting: First, topological sorting is used for each subtask within each task to realize the transformation from graph to list and obtain the topological sorting priority of each subtask. Select the vertex whose input degree is 0 and output it to the list. Delete this vertex and all outgoing edges from the network. Continue to loop until completion and get the topological sorting priority of each subtask.
Then, we define the global priority of subtask j in task i. The global priority depends on the deadline of task i and the topological sorting priority of subtask j.
|
|
ICACT20230136 Slide.09
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The third part is the algorithm.
|
|
ICACT20230136 Slide.08
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
We aim to minimize the total cost of all subtask offloading decisions with the following constraints. For each task, both the transmission cost and the computation cost are considered.
Constraint (7) is the time constraint of the subtask j, indicating that the start time t_ij of subtask j must be after the end time of all its predecessor tasks. Constraint (8) is the demand constraint of task i, indicating that the completion time of the last subtask j can not exceed the deadline of task i. Constraint (9) is the inherent constraint of offloading association.
|
|
ICACT20230136 Slide.07
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
For each DNN task, we measure both the transmission cost and the computation cost of tasks.
The transmission cost of task i is the sum of the transmission costs of all subtasks. The transmission cost of subtask j includes the offloading cost of transmitting subtask j to the offloaded node and the tensor cost of transmitting tensor from all predecessor subtasks to subtask j.
The offloading cost depends on the amount of data and the distance between the initial node of task i and the offloaded node.The tensor cost depends on the tensor size from predecessor subtasks and the distance between predecessor subtasks and subtask j.
The computation cost of task i is the sum of the computation costs of all subtasks. We define SLAV as service level agreement violation, which describes the service level of node k offloading subtask j in task i. The computation cost of task i is the sum of the computation costs of all subtasks. The computation cost of subtask j depends on the amount of data and the service level of offloaded node k.
|
|
ICACT20230136 Slide.06
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
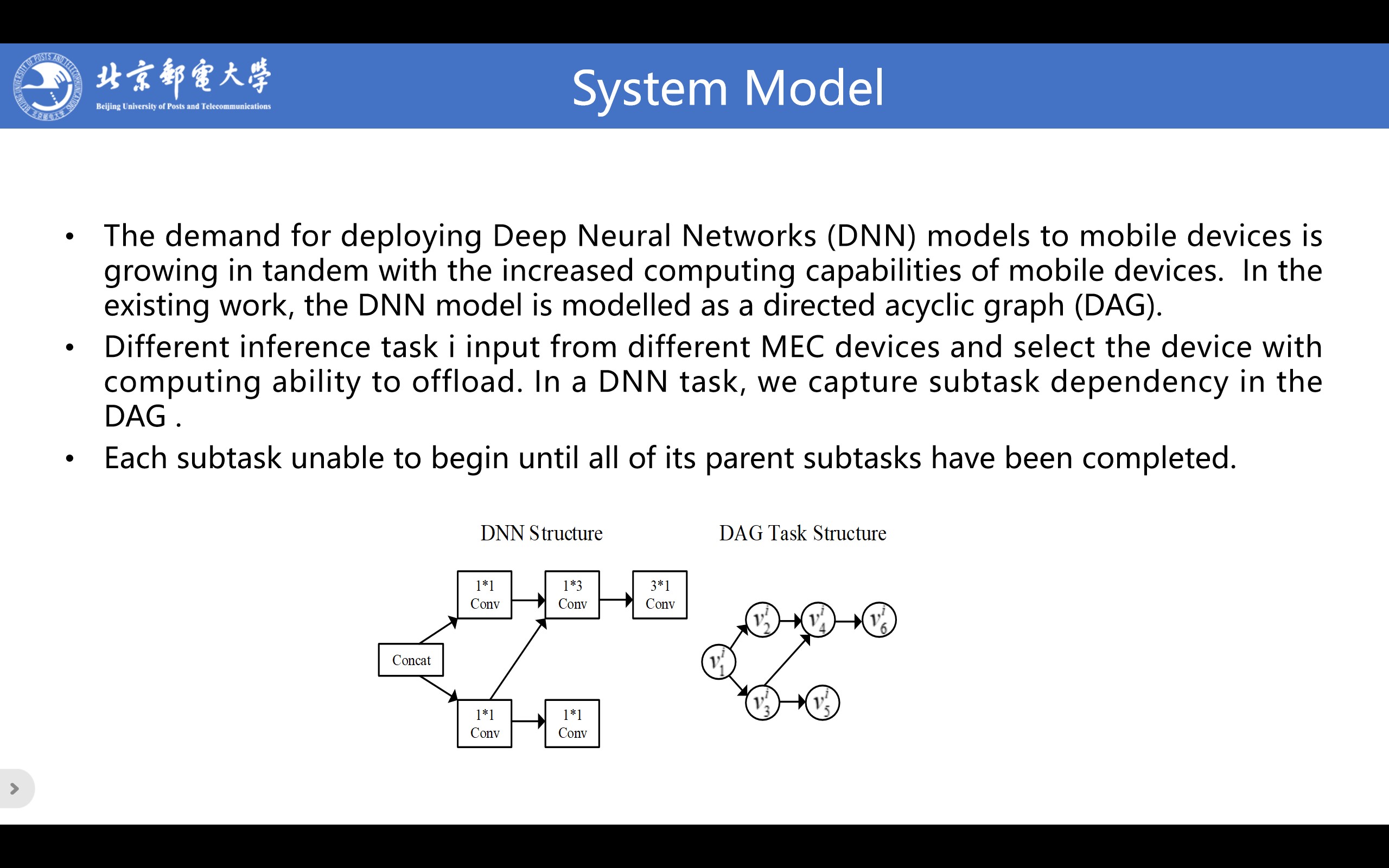 |
The demand for deploying Deep Neural Networks (DNN) models to mobile devices is growing in tandem with the increased computing capabilities of mobile devices. In the existing work, the DNN model is modelled as a directed acyclic graph (DAG).
Different inference task i input from different MEC devices and select the device with computing ability to offload. In a DNN task, we capture subtask dependency in the DAG .
Each subtask unable to begin until all of its parent subtasks have been completed.
|
|
ICACT20230136 Slide.05
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
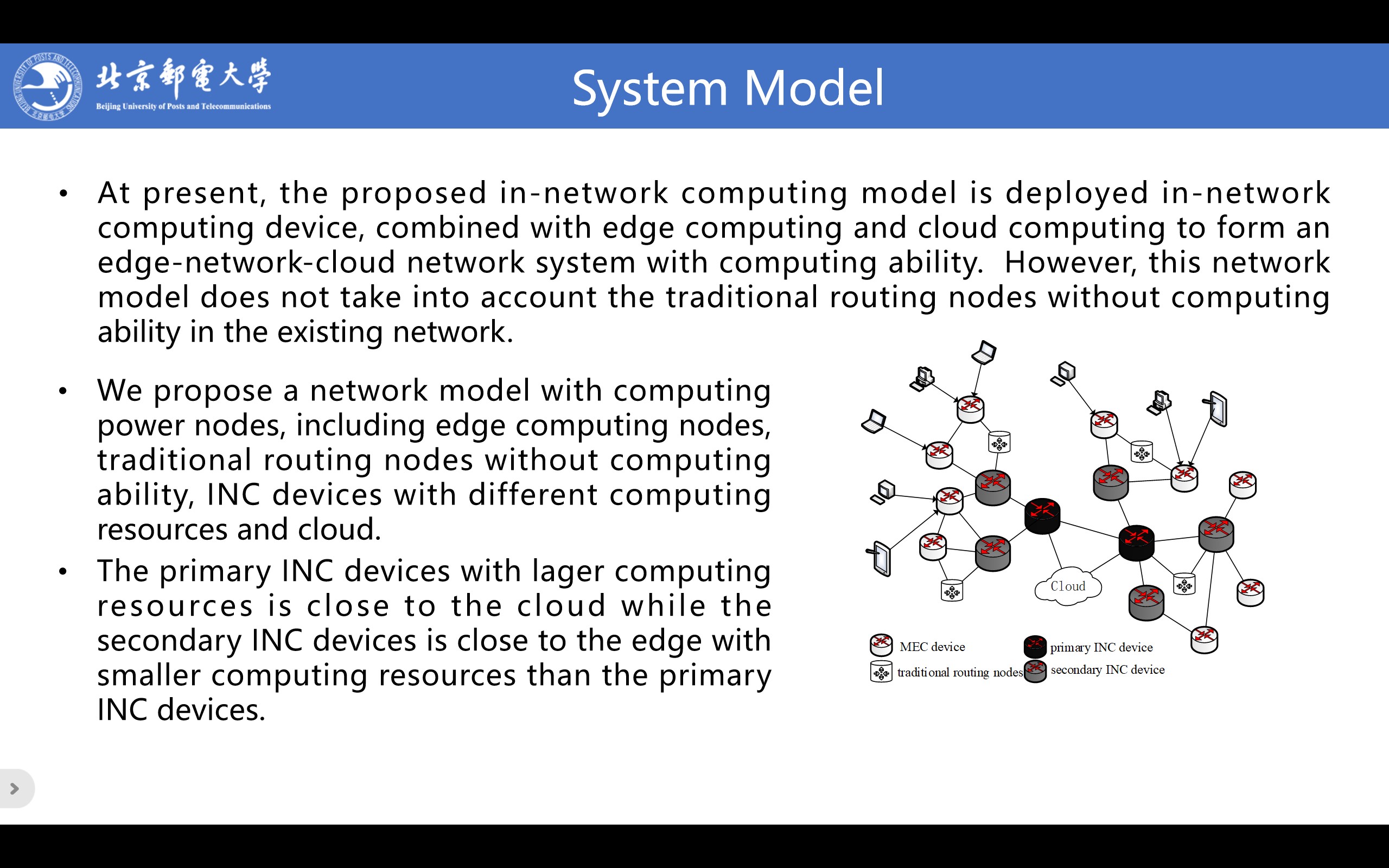 |
At present, the proposed in-network computing model is deployed in-network computing device, combined with edge computing and cloud computing to form an edge-network-cloud network system with computing ability. However, this network model does not take into account the traditional routing nodes without computing ability in the existing network. In this paper, we propose a network model with computing power nodes. The system model diagram is shown in Fig, including edge computing nodes, traditional routing nodes without computing ability, in-network computing (INC) devices with different computing resources and cloud. The primary INC devices with lager computing resources is close to the cloud while the secondary INC devices is close to the edge with smaller computing resources than the primary INC devices.
|
|
ICACT20230136 Slide.04
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The second part is the system model.
|
|
ICACT20230136 Slide.03
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In order to reduce energy consumption of data centers, the industry proposes edge computing model. By offloading some computing tasks to edge devices, cloud servers and user devices reduce power consumption. The emergence of edge computing technology means that the traditional CPU-centric computing model begins to shift to data-centric computing.
In order to further ease the computing pressure in the cloud, the industry puts forward the in-network computing model. In-network computing is a new computing model that schedules processing tasks at the application layer to the network data plane. By offloading computing tasks at the user end to network nodes with computing power, traffic is forwarded and processed at the same time. This means that, without increasing the number of network devices, idle computing power of network devices can be fully utilized to complete some data processing, reduce bandwidth transmission load on the network, and share the processing and computing pressure of the cloud. The advent of network-based computing has changed TCP/IP networks, making them no longer conduits of data that are not aware of applications.
Optimal task offloading is not only to achieve the optimal performance requirements of running applications, but also to efficiently utilize the node resources in the network. Therefore, task offloading is clearly a multi-objective optimization problem, which is NP-hard.
|
|
ICACT20230136 Slide.02
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The first part is the background.
|
|
ICACT20230136 Slide.01
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
We will elaborate from the following four aspects. Background、system model、algorithm and simulation results.
|
|
ICACT20230136 Slide.00
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Hello everyone. I am Lizi Hu from Beijing University of Posts and Telecommunications, China. I would like to thank the ICACT organizers for giving us the opportunity to present our work. My presentation is about "Multi-source DNN task offloading strategy based on in-network computing".
|









