 ICACT20230212 Slide.18
[Big slide for presentation]
ICACT20230212 Slide.18
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! Click!! |
 |
Thank you for listening.
|
|
ICACT20230212 Slide.17
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In this paper, for the lack of attribute sensitivity considerations of existing k-anonymous schemes and how to minimize the amount of information loss, we propose a hierarchical DP-K anonymous data release model based on binary tree clustering. The division of similar data records into the same equivalent class by the binary tree-based clustering algorithm BTCA can improve the effect of clustering, reduce the information loss caused by anonymous data set release, and improve the data availability. The clustered anonymous data sets are reallocated to different privacy budgets according to the privacy rights of the QI attribute, and the hierarchical protection of the data with different degrees of sensitivity can be realized through the differential privacy noise increase mechanism, which enhances the privacy of the data. In the end, the proposed algorithm can effectively reduce the information loss and insufficient privacy protection in the generation process of anonymous data set. However, in this paper, only a single sensitive attribute in the data set is selected. For the data set of high-dimensional sensitive attribute is included, the efficiency and availability of the algorithm may be insufficient, which is also the place to be improved in the future. And, the biggest challenge of fusion difference privacy mechanism is the balance of privacy and availability, how to keep the result data privacy at the same time to reduce noise, based on the tradeoff between utility and privacy to adjust data privacy methods, and create metrics to evaluate the quality of measuring model information loss and privacy protection, is a challenge for future research.
|
|
ICACT20230212 Slide.16
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Summary and Prospect
|
|
ICACT20230212 Slide.15
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
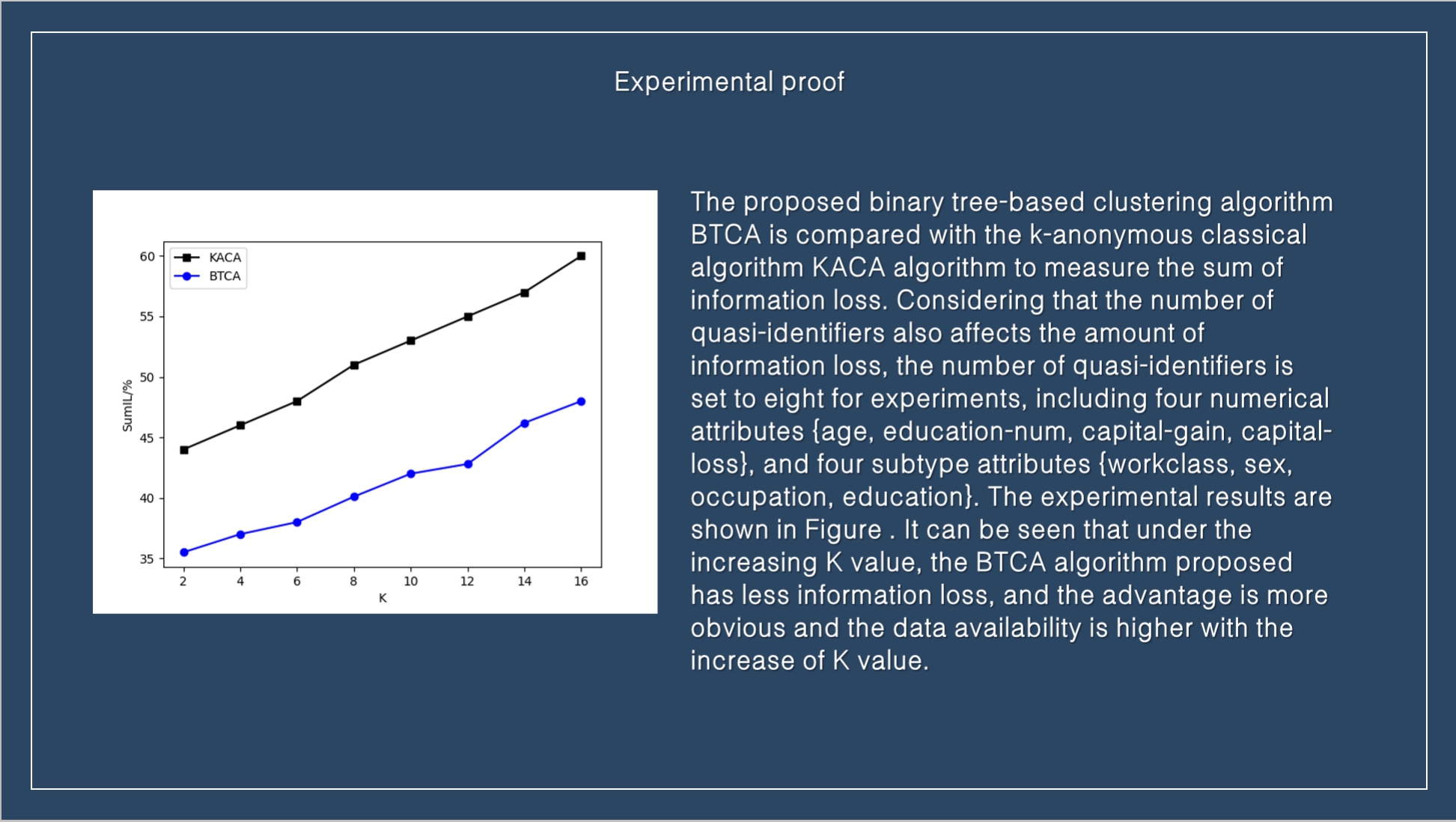 |
The proposed binary tree-based clustering algorithm BTCA is compared with the k-anonymous classical algorithm KACA algorithm to measure the sum of information loss. Considering that the number of quasi-identifiers also affects the amount of information loss, the number of quasi-identifiers is set to eight for experiments, including four numerical attributes {age, education-num, capital-gain, capital-loss}, and four subtype attributes {workclass, sex, occupation, education}. The experimental results are shown in Figure . It can be seen that under the increasing K value, the BTCA algorithm proposed has less information loss, and the advantage is more obvious and the data availability is higher with the increase of K value.
|
|
ICACT20230212 Slide.14
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
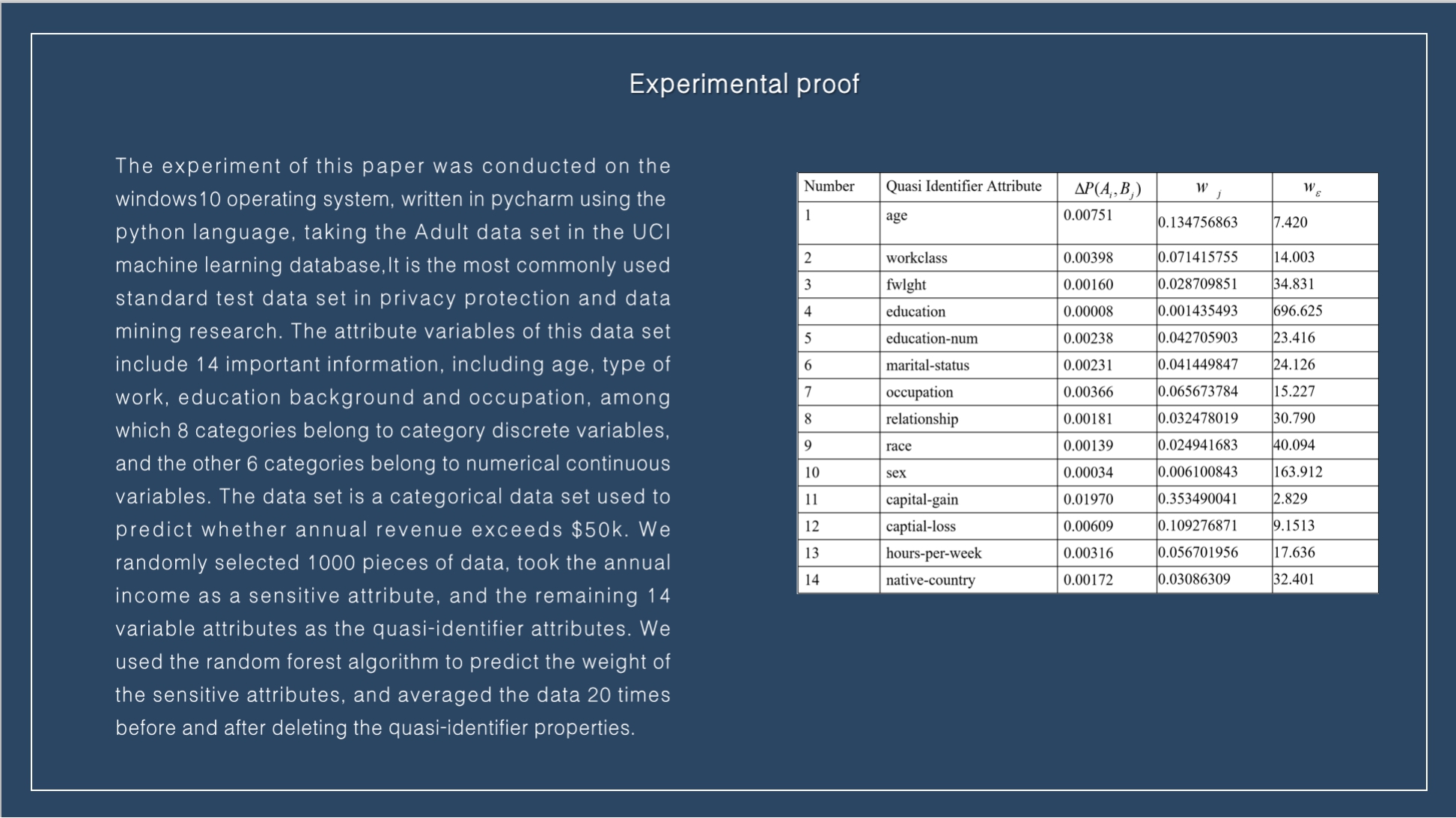 |
The experiment of this paper was conducted on the windows10 operating system, written in pycharm using the python language, taking the Adult data set in the UCI machine learning database,It is the most commonly used standard test data set in privacy protection and data mining research. The attribute variables of this data set include 14 important information, including age, type of work, education background and occupation, among which 8 categories belong to category discrete variables, and the other 6 categories belong to numerical continuous variables. The data set is a categorical data set used to predict whether annual revenue exceeds $50k. We randomly selected 1000 pieces of data, took the annual income as a sensitive attribute, and the remaining 14 variable attributes as the quasi-identifier attributes. We used the random forest algorithm to predict the weight of the sensitive attributes, and averaged the data 20 times before and after deleting the quasi-identifier properties
|
|
ICACT20230212 Slide.13
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Experimental proof
|
|
ICACT20230212 Slide.12
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
This paper combines the differential privacy model to carry out hierarchical noise processing on the original data, and assigns different privacy budgets to each quasi-identifier attribute according to the privacy weight to achieve the purpose of hierarchical protection of differential privacy and protection of anonymous data sets. Laplace noise is used to process numerical data, and exponential mechanism is used to add noise to classified data.
|
|
ICACT20230212 Slide.11
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
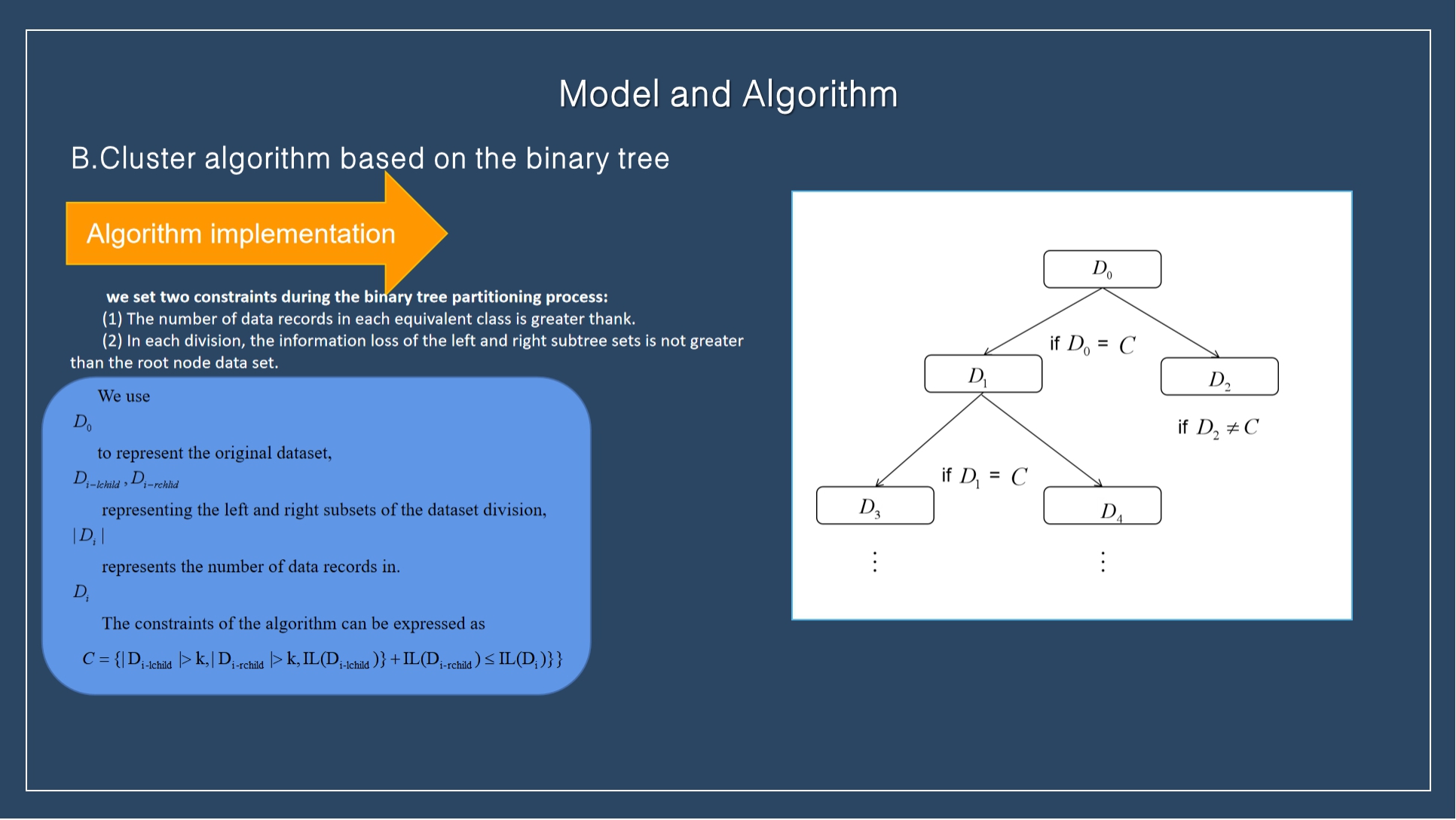 |
In this paper, the binary tree data structure is used to partition the data set, and the minimum information loss is the constraint condition for each partition, so as to reduce the information loss caused by k-anonymity.
First, all records in the data set are regarded as an equivalent set, and all data attributes in the equivalence are minimized. Then, according to the distance calculation formula, the two farthest data records are selected as the cluster centers of the left and right equivalent subsets, and then the distance between other data records and the centers of the two clusters is calculated, which is converted into a 2-means classification problem. After partitioning, it is necessary to determine whether the constraint conditions are met. If not, the partition will be stopped. If the constraint conditions are met, the partition will continue. The binary tree clustering algorithm (BTCA) process is shown in the figure.
|
|
ICACT20230212 Slide.10
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
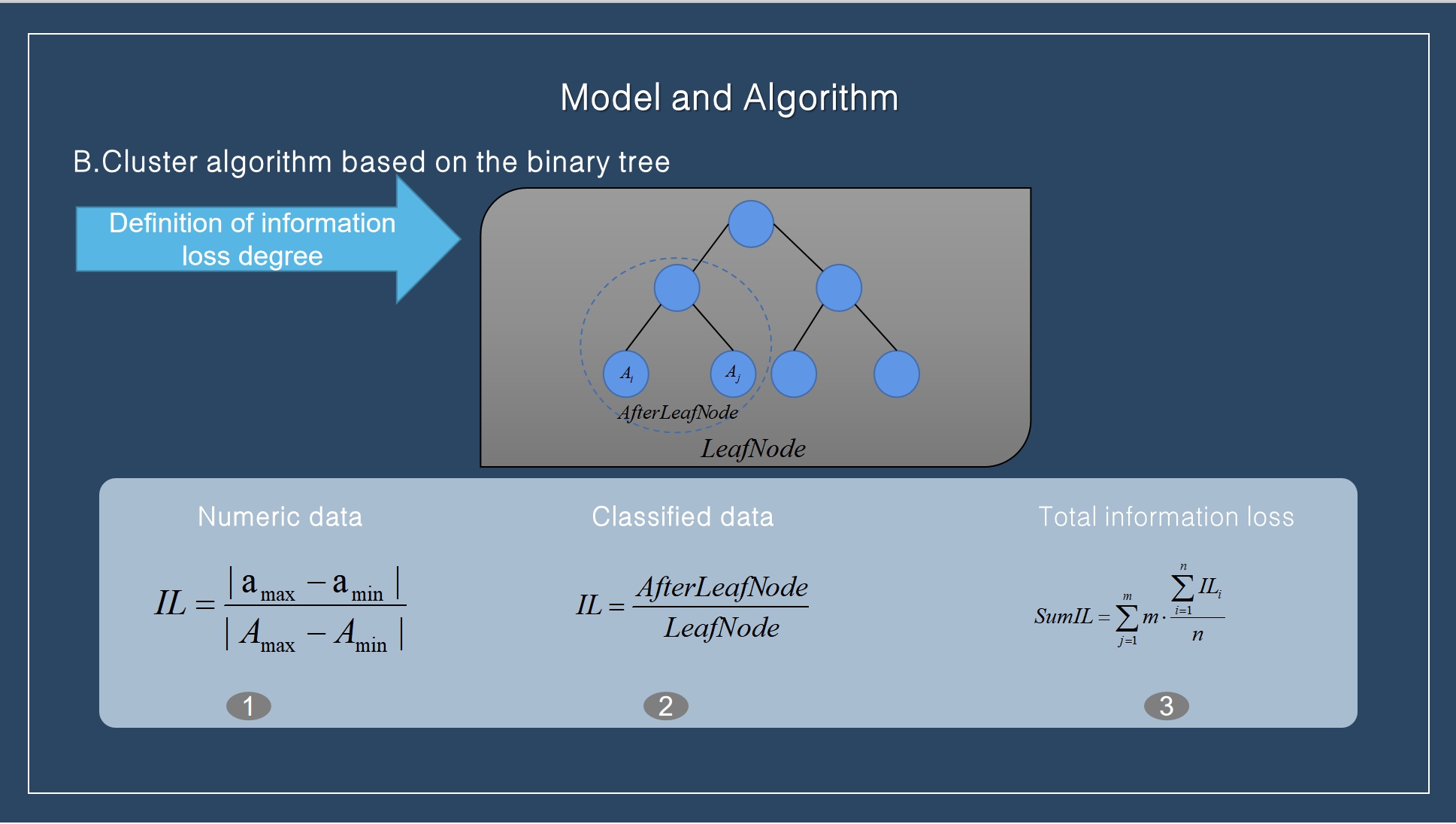 |
The principle of K-anonymity implementation is to generalize the QI attribute of the target identifier and protect the data on the basis of certain information loss, so that the attacker cannot identify it. The purpose of the data set after clustering is to make the similarity of the divided equivalence classes higher, thus reducing the loss of some k-anonymity information. Therefore, in order to measure the information loss degree of the method proposed in this paper more reasonably, according to the characteristics of different attribute types, the information loss after anonymity is calculated from numerical and sub-type attributes respectively, and the calculation methods are (1) and (2). The total information loss calculation method is shown in (3).
|
|
ICACT20230212 Slide.09
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
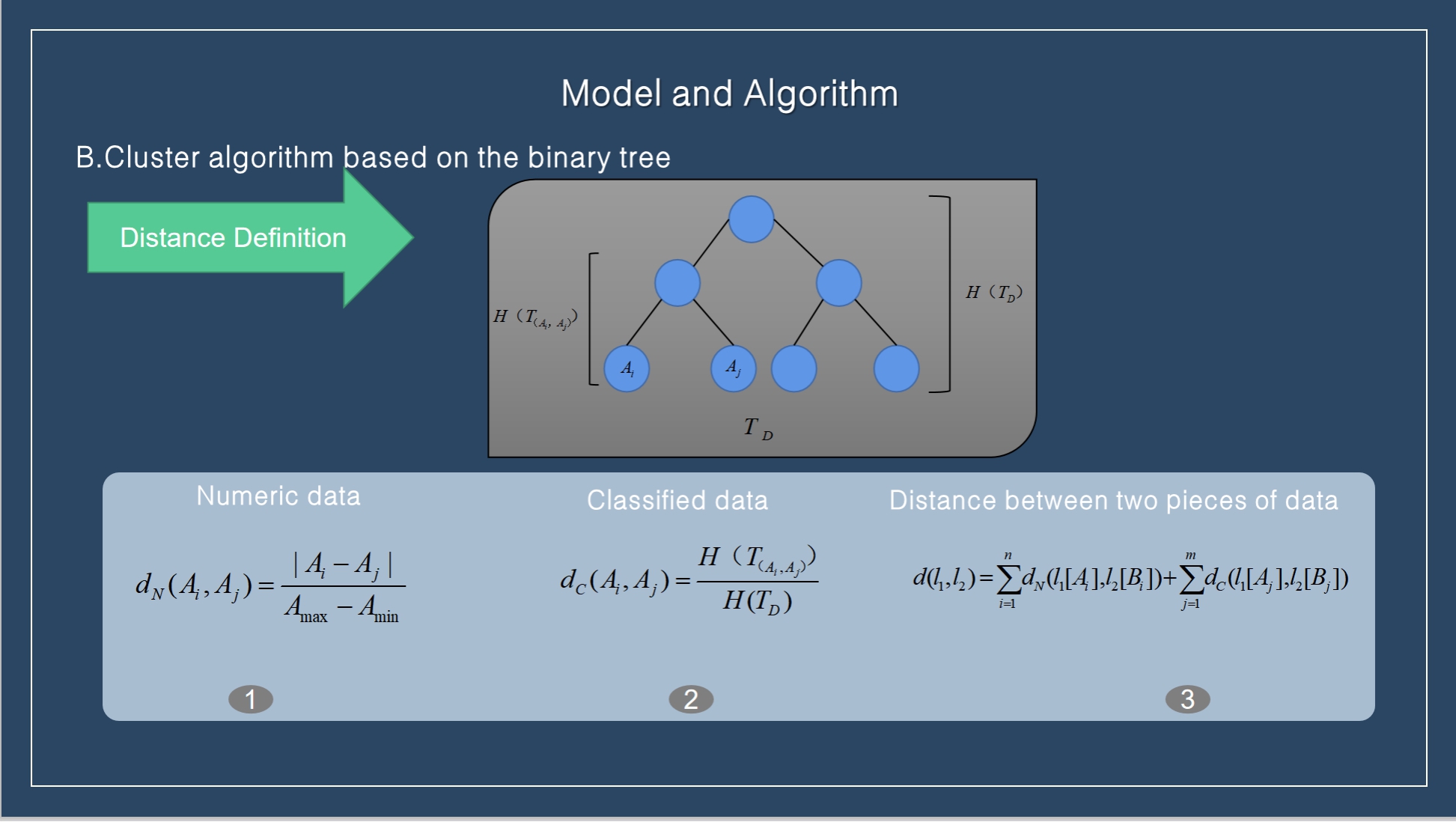 |
We define the distance between any two numerical attribute values as (1). Where, in the formula, represents the maximum and minimum values in the continuous finite value field. Most types of data values have some semantic correlation. In order to better reflect the semantic correlation, we usually use the classification tree (as shown in the figure), and the calculation method is (2). The distance between two data records is equal to the sum of the distances between all their attributes. Assuming that a data table has n numeric attributes and m subtype attributes, the formula for calculating the distance between the two data records is (3).
|
|
ICACT20230212 Slide.08
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
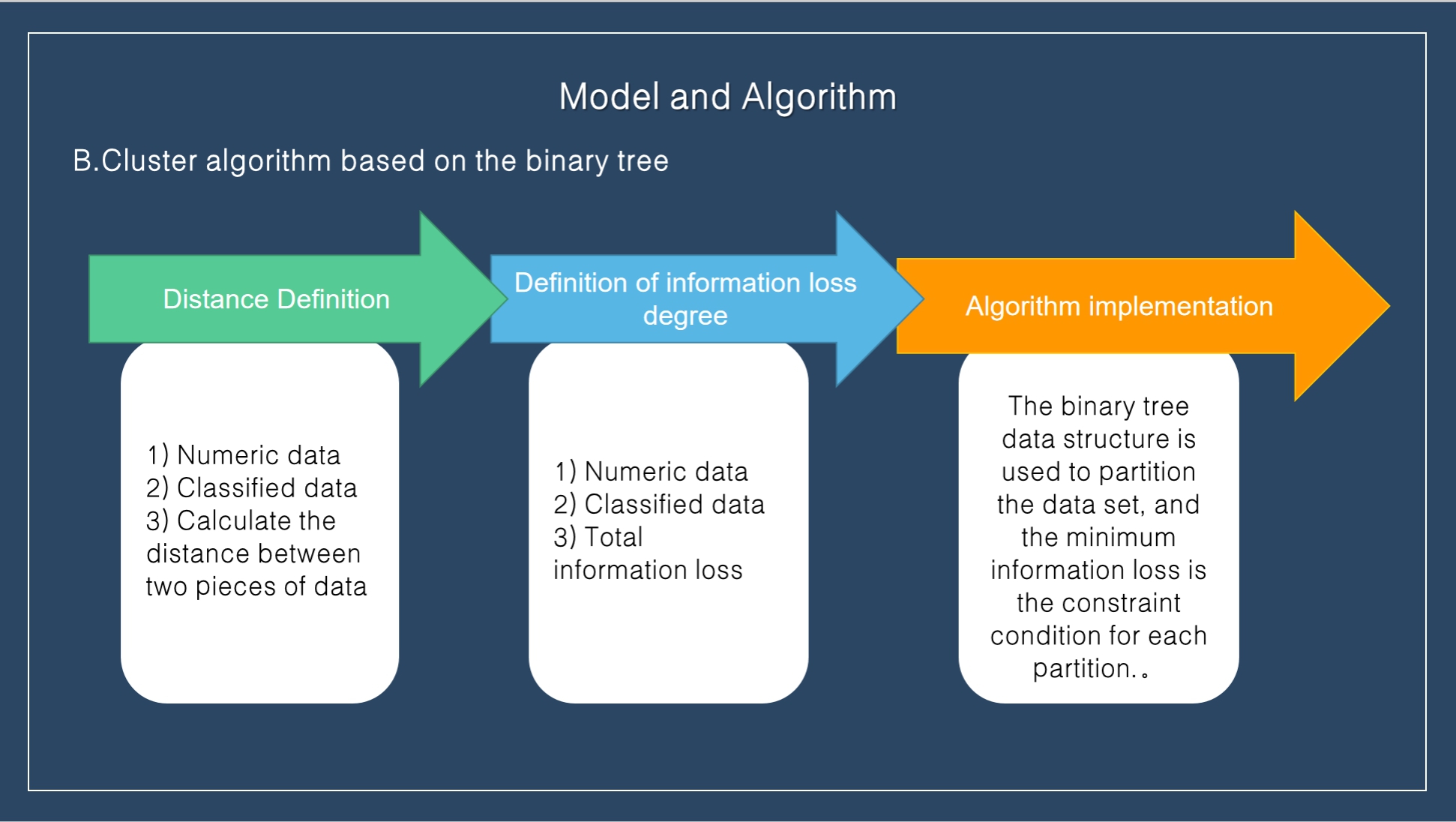 |
The clustering algorithm based on binary tree firstly needs to define the distance between data, and then can measure the information loss in the generalization process, and finally cluster the binary tree at the cost of minimum information loss.
|
|
ICACT20230212 Slide.07
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
We take the correlation between the quasi-identifier attribute and the sensitive attribute as the basis for dividing the degree of privacy protection of the quasi-identifier attribute.
First, the sensitivity of data field attributes is predicted, and the impact of each attribute of data on sensitive attributes is calculated. Suppose a piece of data has n quasi-identifier QI attributes (A1, A2,..., An) and m sensitive attributes (B1, B2,..., Bm). First, calculate the average accuracy rate P1 of predicting sensitive attribute B1 through n QI attributes, and then calculate the average accuracy rate P2 of predicting sensitive attribute with the remaining n-1 QI attributes after deleting the attribute. The difference between the two indicates the impact of the attribute on the prediction of sensitive attribute. The greater the difference, the greater the impact.
Therefore, we can also express the sensitivity of the QI attribute to the sensitive attribute, namely (1). After calculating the sensitivity of n QI attributes to sensitive attribute Bj in turn, normalize them and calculate the privacy weight of each QI attribute, namely (2). After forecasting m sensitive attributes (B1, B2,..., Bm), all sensitivity components of QI attributes and sensitive attributes are obtained × N-type privacy weight matrix, i.e. (3)
|
|
ICACT20230212 Slide.06
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Part II: Model and algorithm
|
|
ICACT20230212 Slide.05
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
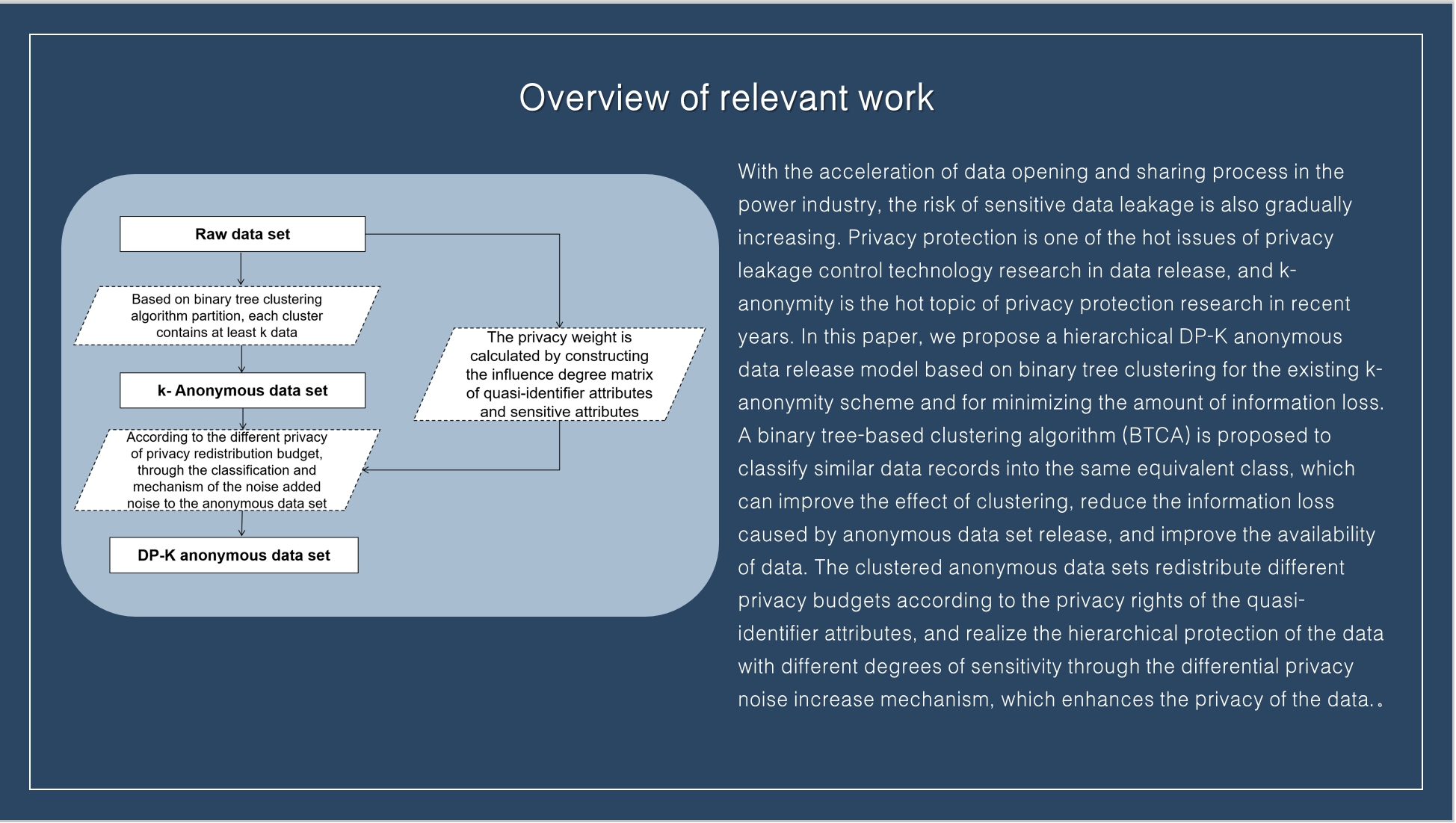 |
In this paper, we propose a hierarchical DP-K anonymous data release model based on binary tree clustering for the existing k-anonymity scheme and for minimizing the amount of information loss. A binary tree-based clustering algorithm (BTCA) is proposed to classify similar data records into the same equivalent class, which can improve the effect of clustering, reduce the information loss caused by anonymous data set release, and improve the availability of data. The clustered anonymous data sets redistribute different privacy budgets according to the privacy rights of the quasi-identifier attributes, and realize the hierarchical protection of the data with different degrees of sensitivity through the differential privacy noise increase mechanism, which enhances the privacy of the data.
|
|
ICACT20230212 Slide.04
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
K-anonymity is a typical representative of data anonymous publishing method. It makes each record indistinguishable from at least k-1 other records by grouping and generalization of the quasi-identifier attribute of the data to be published, thus protecting data privacy. For different attributes of a dataset, or different columns. According to its function, it can be roughly divided into three types: identifier (ID), quasi identifier (QI), and sensitive data (SA). The general research goal of data privacy protection is to properly desensitize the identity attributes on the basis of deleting the identity attributes to maintain the balance between privacy and availability. An identifier can uniquely identify a piece of data, and the combination of different quasi-identifiers can also identify a piece of data. As the name implies, private data is the object of privacy protection.
The first step of k-anonymous data anonymity is to delete any explicit identifier that can directly define personal identity. Then, through the generalization technology, each record in the published data set cannot be distinguished from the k-1 record set that shares the same quasi-identifier value. These values are called "equivalent classes". K-anonymity technology can guarantee the following three points:
(1) Resist member inference attacks, and attackers cannot determine whether a target person is in the public data
(2) Sensitive information protection, given that an attacker cannot confirm whether he has a sensitive attribute
(3) Against reverse analysis attacks, attackers can't confirm who a piece of data corresponds to
|
|
ICACT20230212 Slide.03
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
As a new factor of production in the era of digital economy, data realizes value creation in the flow and sharing, and at the same time, it also faces huge risk of leakage. Electric power data involves regulation and control data, marketing data, production equipment data, human and property management data, etc., which are vital tangible assets of enterprises. Data security and privacy protection are the core issues in the process of power data application and value mining. The problem of privacy disclosure in the process of data publishing for the purpose of information sharing and data mining is also increasingly prominent, so how to effectively protect private sensitive information from disclosure while realizing information sharing is particularly important. At present, there are three main methods to protect private data: (1) k-anonymity. The most widely used technology now is k-anonymity. When enterprises publish user data, they will hide the unique identity such as ID number or name to protect users' privacy. However, this method cannot resist link attack and background knowledge attack; (2) Data disruption. This method uses technologies such as scrambling, distortion and randomization to disrupt the original data, making the data lose authenticity and integrity, and the attacker cannot obtain the real data, but the availability of the data is greatly reduced; (3) Data encryption. Combining cryptography with data security, we use homomorphic encryption, asymmetric encryption technology and other mechanisms to form distributed security computing to support the work of privacy protection. For example, secure multi-party computing, but the problem of this method is that it requires too much computing resources and costs too much.
|
|
ICACT20230212 Slide.02
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Part I: Overview of relevant work
|
|
ICACT20230212 Slide.01
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The demonstration of this article is divided into four parts, which are related work overview, model and algorithm, experimental proof, summary and prospect.
|
|
ICACT20230212 Slide.00
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Hello, my name is Xia Yuxiao. For ICACT 2023, I discussed with several partners about data anonymous publishing technology. Our speech today is about the improved solution of traditional K anonymity technology, which we call hierarchical DP-K anonymous data release model based on binary tree.
|









