 ICACT20220068 Slide.15
[Big slide for presentation]
ICACT20220068 Slide.15
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! Click!! |
 |
Thanks!
Please feel free to leave question & comments.
|
|
ICACT20220068 Slide.14
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Part 5 Conclusion
In this paper, a new active learning clustering based on density peak clustering has been proposed. By soliciting label from users after a small set of questions, our algorithm can collect a good set of cluster centers and can detect clusters in straightforward. Experiments conducted on both artificial data and UCI data show the effectiveness of our algorithm and hence providing a new clustering technique for real applications. In the near future, some improvement of density peak clustering will be examined and applied to some applications such as image data or text data.
|
|
ICACT20220068 Slide.13
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
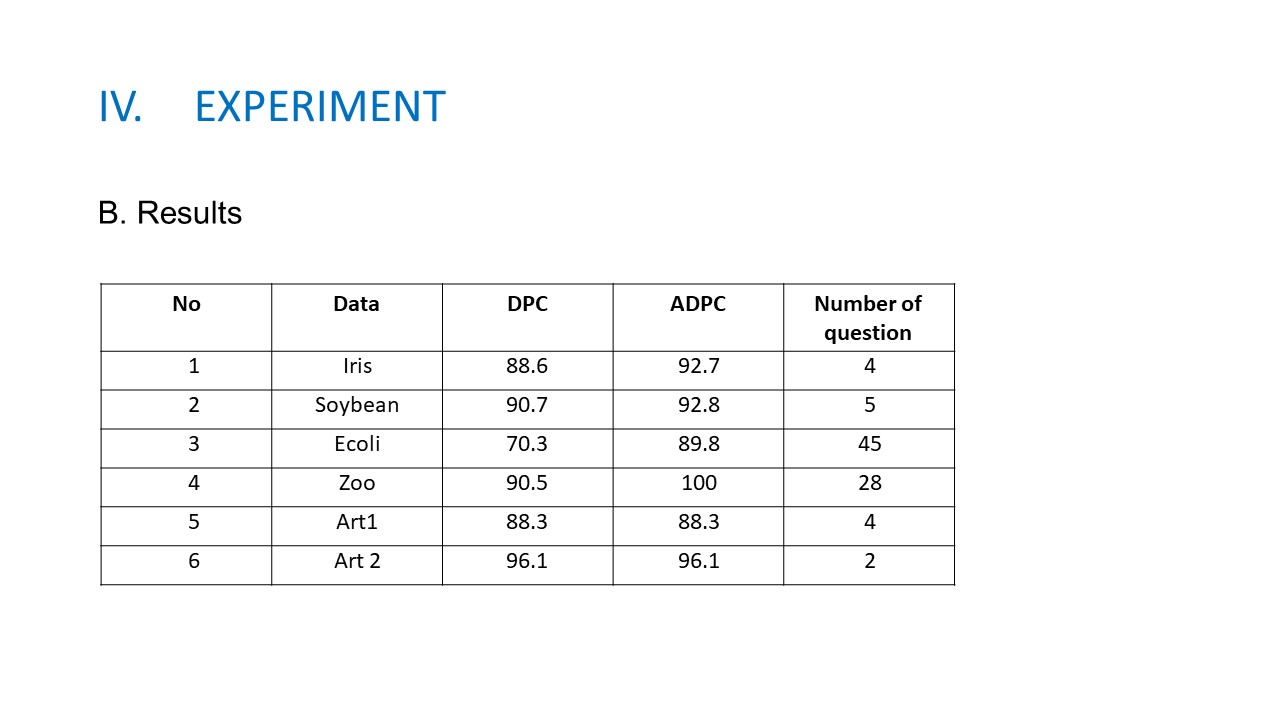 |
B. Experiment results. Table 2 presents the Rand Index measure obtained by two methods DPC and ADPC. From the table, we can see that, with some questions proposed for users, we can collect exactly the number of clusters and hence the quality of clustering process had been improved. Some details explanations will be made as follows. For the Iris data set, it has three clusters in which two clusters are overlaps, so DPC can not detect exactly the number of clusters as mentioned in the figure 3. In contrary, by soliciting label from users for data points with high density, we can collect the cluster centers and the clustering results will be improved. For Soybean data set, the explanation is similar to Iris, DPC cannot detect four clusters, using ADPC, we can detect four cluster centers after five questions and the result is enhanced. For Ecoli data set, it is an imbalanced data with cluster size from 2 to 142, so we need 45 questions to collects the labels for cluster centers and ADPC obtained the RI with 89.8% while DPC cannot detect the number of clusters and ADPC obtained the good results compared with DPC. The results can be explained by the fact that real data sets always have complex distribution and the peak may appear in many regions in each cluster. Using decision graph to identify the cluster centers may have some troubles. Figure 4 shows the decision graph of Ecoli data set. It can be seen from the figure that it is not easy to choose the good cluster centers without using domain experts.
|
|
ICACT20220068 Slide.12
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
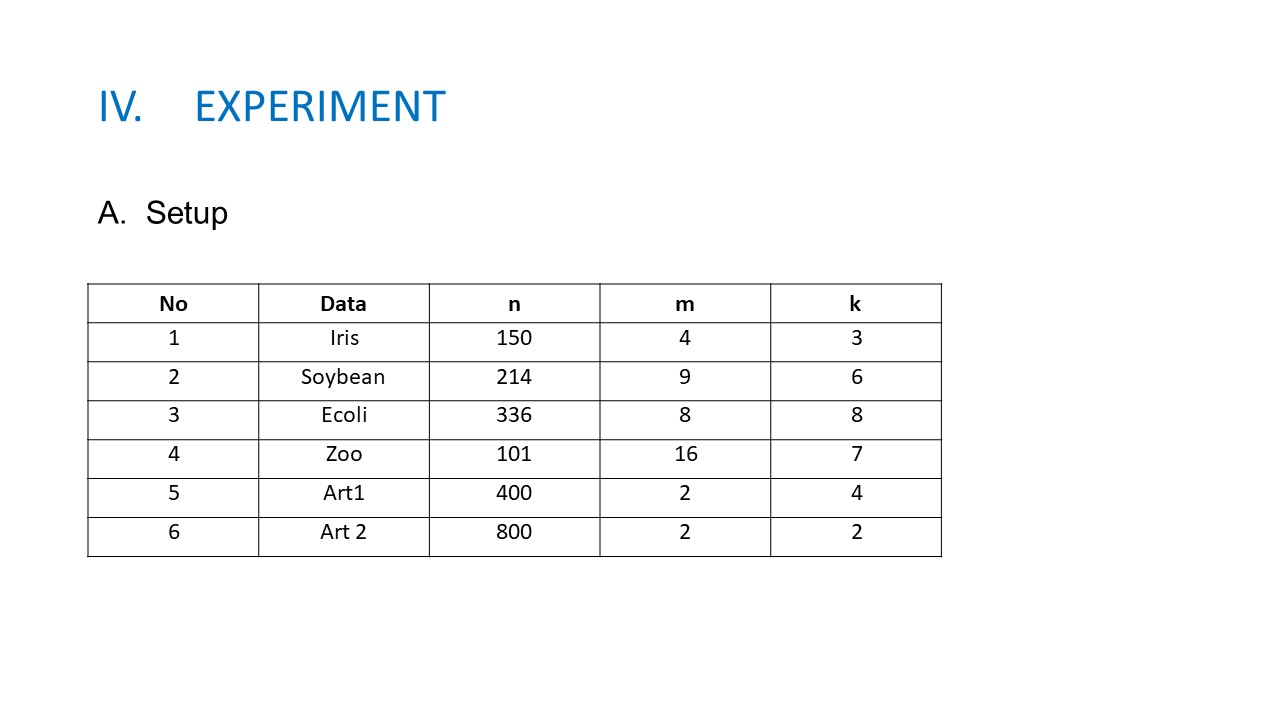 |
Part 4 EXPERIMENTS. A. Experimental setup To evaluate our new algorithm, we have used four data sets from UCI machine learning and two data sets are generated follow the Gaussian distribution. The details of these data sets are presented in Table 1, in which n, m, and k respectively are the number of data points, the number of features, and the number of clusters. To evaluate the clustering results we have used the Rand Index (RI) measure, which is widely used for this purpose in different researches. The RI calculates the agreement between the true partition (P1) and the output partition (P2) of each data set. To compare two partitions P1 and P2, let u be the number of decisions where xi and xj are in the same cluster in both P1 and P2. Let v be the number of decisions, where the two points are put in different clusters in both P1 and P2.
The value of RI is in the interval [0…1]; RI = 1 when the clustering result corresponds to the ground truth or user expectation. In our experimentation, we use the Rand Index in percentage. The higher the RI, the better the result of clustering.
|
|
ICACT20220068 Slide.11
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Algorithm 2: Active learning for density peak clustering
|
|
ICACT20220068 Slide.10
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Part 3 THE PROPOSED METHOD. The key different of our algorithm compared with the original DPC is the adding of a loop for soliciting label from users to identify cluster centers. This is the active loop based on the uncertainty strategy. To this aim, a loop (step 5 to step 8 in Algorithm 2) is added to form a user or question process. At each step of the loop, we will choose the point, so that the multiple of rho and delta values, is maxima and solicit users to get its label. The loop process will stop by users; it means that we have collected enough cluster centers. After that, the strategy as in the DPC, is applied for clustering process and gets final results. The detail of algorithm is presented in Algorithm 2.
|
|
ICACT20220068 Slide.09
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
B. Active learning. Active learning is a sub-field of machine learning topic. The aim of active learning is to develop algorithms, that can learn new feedback at each step in a question-answering process. In the context of semi-supervised clustering, active learning aims to select the most useful constraints, so that they not only boost the clustering performance, but also minimize the number of questions to the user/expert. For active learning methods, we assume that the users/experts are always ready, for answering the question proposed by active learning process. For example, Basu et al, introduced a method for collecting constraints, in which at each step, the algorithm will propose a question, about the relating between two points, and the users will answer the pair of point is, must-link or cannot-link; an active learning method applied for K-means clustering has presented, the idea is using K-means to partition data set into large number of clusters, after that queries will be asked for each pair of clusters, and the process will finish, when users have been satisfied about the final results.
|
|
ICACT20220068 Slide.08
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Here the detail of the Algorithm 1: Density peak clustering process
|
|
ICACT20220068 Slide.07
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In 2014, Rodriguez and Laio proposed the density peak clustering which is the density based clustering. With only one parameter, called dc, the DPC uses the parameter to estimate the density of each data point and create a decision graph. From the decision graph, we can decide the number of clusters for each data set. Firstly, the local density of a point xi. Secondly, the d(xi) is defined as the minimum distance between the point i and any other point with higher density. Thirdly, the decision graph is constructed in which the x-axis and the y-axis are respectively the rho and delta values for every point in the data set
Finally, the clusters will detect by using peaks with a propagation label process. The detail steps of the DPC are presented in Algorithm 1.
|
|
ICACT20220068 Slide.06
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In this part, we will present the principle of density peak clustering and active learning method applied for clustering problem.
|
|
ICACT20220068 Slide.05
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
The algorithm has been attracted a lot of attention in research communities, in which most of works try to improve clustering quality. Several thousands of papers have cited the DPC algorithm up to date. In this paper, we focus on the two following problems:
First problem, In real data set, the distribution of data may not follow some normal distributions. So it is not easy to match real cluster centers and peaks as DPC does. Second problem, In each local region of data set, it has several peaks so these peaks may belong to the same cluster, this problem can generate some mistakes in the choosing cluster center process. To tackle with these problems, in this paper we propose a new active density peak of clustering to improve clustering process by soliciting some labels from users to identify exactly the number of clusters for each data set. The experiments conducted on some UCI data sets show the effectiveness of our methods.
|
|
ICACT20220068 Slide.04
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
In general, clustering methods can be grouped in some kinds including partition methods, hierarchical methods, density based method and model based methods. Partition clustering aim to divide the data objects into k clusters using an objective function for optimizing. We can cite here some major algorithms such as K-means and Fuzzy C-Means. Hierarchical clustering (HC) algorithms usually organize data into a hierarchical structure according to the proximity matrix. The results of HC are usually depicted by a binary tree or dendrogram. From the organized dendrogram, we can decide which level of dendrogram may cut off to form the final clusters. The idea of density based clustering detects clusters by identifying those regions where each region is a dense group of points. DBSCAN and SNN are two methods based on the density estimation concept. Model-based techniques assume that the distribution of data fit a model mathematic, and the finding clusters are equal to an optimization process to fit between mathematic model and data distribution. In 2014, Rodriguez and Laio introduced the density peak clustering method that is based on density estimation method. The DPC has some advantage compared with DBSCAN or other techniques as follow: it needs to use only one parameter and it can detect clusters with different shape and densities with noises.
|
|
ICACT20220068 Slide.03
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Part 1 INTRODUCTION.
The goal of clustering is to divide a set of objects into a finite and discrete set of clusters, in which objects in the same cluster are similar, while objects in different cluster are dissimilar follow some criteria of user domain.
Though clustering algorithms have long history, nowadays clustering topic has still attracted a lot of attentions, because of the need of efficient data analysis tools in many applications, such as web mining, spatial database analysis, GIS, textual document collection, image segmentation, etc.
Given a data set of objects, clustering can detect the relation between data objects and the hidden structure of whole data objects and hence, it is the important tool in the data mining and knowledge discovery process.
|
|
ICACT20220068 Slide.02
[Big slide for presentation]
|
Chrome Text-to-Speach Click!! |
 |
Today, I will introduce to you five parts.
One is introduction
Two is related works
Three is our proposal method
Four is the experiments
And finally, the conclusion
|
|
ICACT20220068 Slide.01
[Big slide for presentation]
[YouTube] |
Chrome Text-to-Speach Click!! |
 |
Hello everyone. My name is Hai-Minh Nguyen. It is my pleasure to present our work in ICACT 2022, Paper Title is Active Learning for Density Peak Clustering. Density peak clustering (DPC) is one of the most interesting methods in recent years. By using only one parameter, the algorithm can identify the number of clusters using peak estimation based on density and detect clusters in a single step. Although the DPC has lots of advantages, however, for some real applications, it is not easy to identify exactly the number of clusters because of the complex data distribution. In this paper, we propose a new active density peak clustering that aim to improve the clustering process for DPC. The main idea of our algorithm is adding a loop of active cluster centers selection for getting label from users. Experiments results show the effectiveness of our proposed solution.
|









